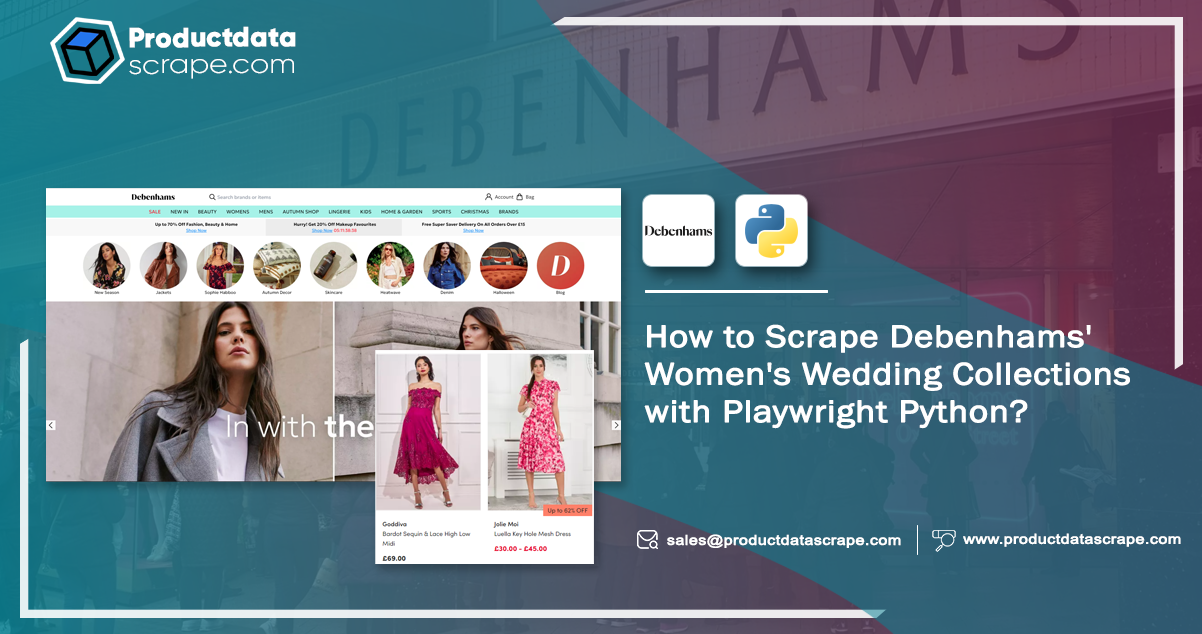
Debenhams, a renowned fashion destination, offers an extensive range of wedding collections tailored to various styles and preferences. However, navigating such a vast and diverse collection can be overwhelming for brides-to-be and enthusiasts alike, especially when keeping up with the latest trends and designs.
Fortunately, web scraping Debenhams data comes to the rescue! Using Playwright, a powerful automation library, we can automate extracting valuable data from Debenhams' website. Our guide provides step-by-step instructions and code snippets for scraping product details, images, prices, and more, granting you access to a wealth of information for exploration and analysis.
Playwright is an automation library that enables browser control, including Chromium, Firefox, and WebKit, using programming languages like Python and JavaScript. It's an ideal tool for web scraping fashion data because it allows automation of tasks such as button clicks, form filling, and scrolling. We will leverage Playwright to navigate through categories and gather product information, including names, prices, and descriptions.
In this tutorial, you'll learn to use Playwright and Python to scrape data from Debenhams' website. We will extract various data attributes from individual product pages.
List of Data Fields
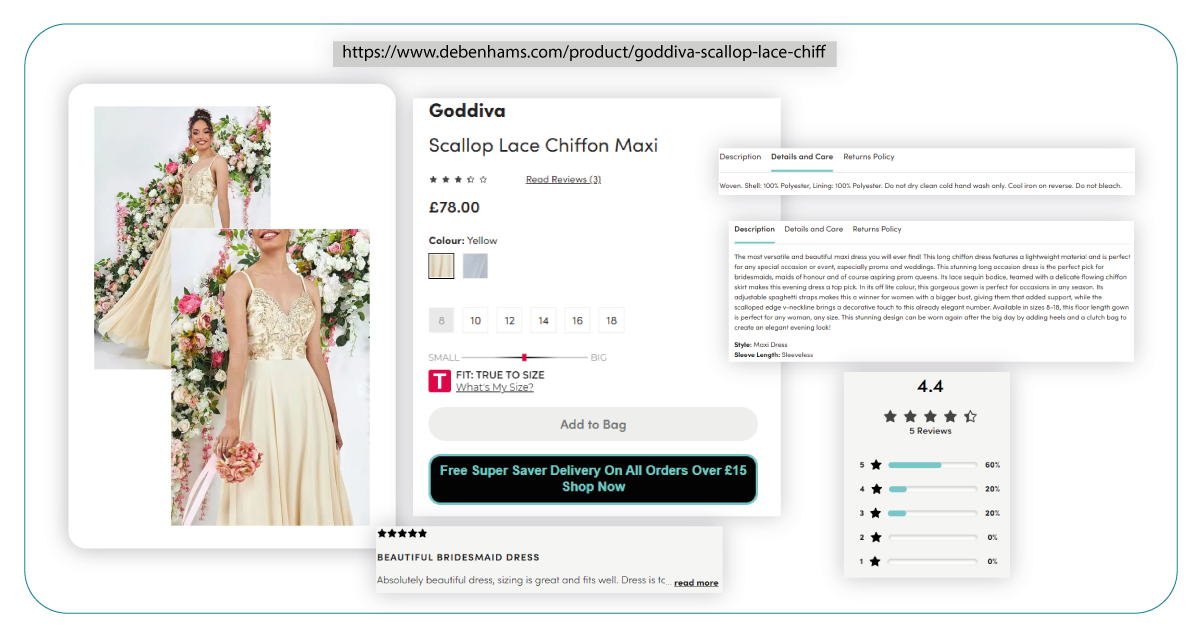
- Product URL: The link to the products.
- Product Name: The name of the products.
- Brand: The brand of the products.
- SKU: The stock-keeping unit of the products.
- Image: Product images.
- MRP (Maximum Retail Price): The listed retail price.
- Sale Price: The price discount.
- Discount Percentage: The range of discounts.
- Number of Reviews: Product review counts.
- Ratings: Ratings of products.
- Color: Product color options.
- Description: Product descriptions.
- Details and Care Information: Additional product details, including material and care instructions.
Here's a comprehensive guide on using Python and Playwright for scraping wedding collection data from Debenhams' website.
Import Necessary Libraries

To begin online retail data scraping, we must import the necessary libraries that will enable us to interact with the website and extract the desired information.
- 're' Module: This module is essential for working with regular expressions.
- 'random' Module: It facilitates the generation of random numbers and helps create test data or randomize test orders.
- 'asyncio' Module: We utilize the 'asyncio' module to manage asynchronous programming in Python, a necessity when working with Playwright's asynchronous API.
- 'pandas' Library: 'pandas' is employed for data manipulation and analysis. In this tutorial, it stores and manipulates the data obtained from the tested web pages.
- 'async_playwright' Module: This module represents Playwright's asynchronous API, which is crucial in automating browser testing. It enables concurrent operations, enhancing the efficiency and speed of tests.
These libraries collectively support various aspects of our browser testing automation using Playwright, encompassing tasks like generating test data, handling asynchronous operations, data storage, manipulation, and automating browser interactions.
Implementing Request Retry with Maximum Retry Limit
Request retry is a fundamental aspect of web scraping department stores data, serving as a mechanism to handle transient network errors or unexpected website responses. Its primary goal is to resend the request if it fails initially, thereby increasing the likelihood of a successful outcome.
Before proceeding to the URL, the script incorporates a retry mechanism to account for potential timeouts. This mechanism employs a while loop, continuously attempting to access the URL until the request is successful or reaches the maximum allowable number of retries. If the maximum retry limit exceeds, the script triggers an exception.
The provided code defines a function responsible for requesting a specified link and initiating retries if the initial attempt fails. This function proves particularly valuable in scraping Debenhams women's clothing data, where requests might encounter timeouts or network-related issues.

In this section, the function initiates a request to a specific link utilizing the 'goto' method from the Playwright library's page object. If the initial request encounters failure, the function automatically retries it for a maximum of five times, a value defined by the MAX_RETRIES constant. Between each retry attempt, the function introduces a random delay ranging from 1 to 5 seconds, achieved through the use of the asyncio.sleep method. This deliberate delay is incorporated to avoid rapid, repeated retries, which could exacerbate the likelihood of further request failures. The 'perform_request_with_retry' function has two essential arguments: 'page' (representing the Playwright page object responsible for the request) and 'link.'
Scrape Product URLs
Our task involves the extraction of product URLs. This process, referred to as "product URL extraction," entails systematically collecting and organizing URLs associated with products listed on a web page or online platform. While the Debenhams website displays all its products on a single page, accessing additional items necessitates clicking the "Load More" button. However, rather than resorting to manual interactions with this button, we've identified a consistent URL pattern alteration following each "Load More" click. Leveraging this discerned pattern, we've streamlined the process of effortlessly scraping Debenham's product URLs.

The 'get_product_urls' function is an asynchronous function that inputs a 'page' object. It initializes an empty set called 'product_urls' to store the unique URLs of the products. The code operates within a while loop until scraping of all product URLs. It employs 'page.querySelectorAll()' to locate all elements with a specific class corresponding to the product links on the page. It breaks out of the loop if there are no elements, indicating scraping of all products.
Within the loop, the code iterates through each found element, representing a product link. It utilizes 'item.getAttribute('href')' to extract the value of the 'href' attribute, which contains the relative URL of the product. The base URL of Debenhams is then appended to the relative URL to obtain the whole product URL, which adds to the 'product_urls' set.
After scraping all the product URLs on the current page, the code calculates the total number of products obtained and prints it to the console for progress tracking. This section checks for a "Load More" button on the page by employing 'page.querySelector()' with a specific CSS selector for the button. If the button exists, it extracts the URL from its 'href' attribute and prepares the complete URL by appending the base Debenhams URL. Subsequently, it initiates an asynchronous request to navigate to the next page using the 'perform_request_with_retry' function. Terminate the loop if there is no "Load More" button, as there are no more products to scrape.
This code efficiently utilizes asynchronous programming, enabling it to manage multiple requests and seamlessly navigate through pages. By leveraging Playwright's capabilities, the script effectively scrapes all product URLs without requiring manual interaction with the "Load More" button. This automated approach is a powerful solution for exploring the world of women's wedding collections at Debenhams.
Scrape Product Name
The subsequent task involves extracting the names of the products from the web pages. The extraction of product names holds significant importance when gathering data from websites, particularly in e-commerce platforms like Debenhams, where a diverse array of products is available. The online retail data scraping services enable efficient cataloging and analysis of the various items within their collections..

The 'get_product_name' function specializes in extracting the names of products from a given webpage. Implement it using asynchronous programming to handle interactions with web pages efficiently. This function accepts a 'page' object as input, representing the scraping of the webpage, and its primary objective is to locate and retrieve the product's name from the page.
Within a try-except block, the code attempts to locate the HTML element containing the product name using the 'page.querySelector()' method. It searches for an element with the class '.heading__StyledHeading-as990v-0.XbnMa,' which appears to be the specific class associated with product names on the Debenhams website. If the element is available, extract the product name using the 'textContent()' method with the help of Debenhams data scraper.
The 'await' keyword awaits the asynchronous operation of finding and retrieving the product name. It allows the function to proceed asynchronously with other tasks while waiting for the product name to be retrieved. If issues arise while locating or retrieving the product name (e.g., the specified element class does not exist on the page, or an error occurs), execute the code inside the 'except' block. In such cases, the product name is "Not Available" to indicate the unavailability of the product name.
The 'get_product_name' function with the previously explained 'get_product_urls' function to scrape the URLs and names of products from the Debenhams website. By leveraging these two functions in tandem, you can create a robust web scraping tool for gathering valuable data about the captivating world of women's wedding collections offered by Debenhams.
Scrape Brand Name
In web scraping, retrieving the brand name associated with a specific product is a crucial step in identifying the manufacturer or company responsible for producing that product. When delving into the domain of women's wedding collections, the brand behind a product can convey significant information regarding its quality, style, and craftsmanship. The process of extracting brand names parallels that of extracting product names – we systematically locate the pertinent elements on the page using a CSS selector and subsequently extract the textual content from those elements.

The 'get_brand_name' function extracts the brand name associated with a product from a given webpage. Like its predecessors, this function uses asynchronous programming to adeptly manage interactions with web pages. Much akin to the prior functions, 'get_brand_name' takes a 'page' object as input, representing the webpage targeted for scraping. Its primary objective is to locate and retrieve the product's brand name from the page.
The code aims to find the HTML element containing the brand name using the 'page.querySelector()' method within a try-except block. It meticulously seeks out an element characterized by the class '.text__StyledText-sc-14p9z0h-0.fRaSnP,' which appears to be the specific class associated with brand names on the Debenhams website.
If the element is available, extract the brand name from the element employing the 'textContent()' method. The 'await' keyword is thoughtfully employed to patiently await the completion of the asynchronous operation involved in finding and fetching the brand name. This design allows the function to seamlessly continue with other tasks while waiting patiently to procure the brand name.
In the event of any setbacks encountered during the quest to find or retrieve the brand name (such as the specified element class being absent on the page or encountering an error during the process), the code encapsulated within the 'except' block springs into action. In such cases, set the brand name to "Not Available," signifying the unattainability of the brand name.
This 'get_brand_name' function harmonizes splendidly with the previously elucidated 'get_product_urls' and 'get_product_name' functions, collectively enabling the scraping of URLs, names, and brand names of products from the Debenhams website. By skillfully orchestrating these functions in tandem, you have the power to construct a comprehensive web scraping tool that adeptly assembles valuable data from the enchanting realm of women's wedding collections featured by Debenhams, inclusive of the products' brand names.
Moreover, with the same technique Scrape Debenhams' Women's Wedding Collections with Playwright Python to collect attributes such as SKU, Image, MRP, Sale Price, Number of Reviews, Ratings, Discount Percentage, Color, Description, and Details Care Information. This versatile approach extracts these attributes with precision.
Scrape SKU
SKU, which stands for "Stock Keeping Unit," represents a distinctive alphanumeric code or identifier utilized by retailers and businesses for monitoring and overseeing their inventory. SKUs assume a pivotal role in the realm of inventory management and data analysis. They serve as the foundation for monitoring stock flow, streamlining point-of-sale transactions, and enhancing the efficiency of supply chain operations.

Image Extraction
Images wield tremendous influence in fashion and e-commerce, serving as potent visual representations of exquisite products. Discovering the methods to capture and store these compelling images is paramount for constructing a comprehensive catalog and effectively presenting the allure of each bridal masterpiece. In our current endeavor, we extract images as image URLs. Upon accessing these URLs, we found enchanting images that eloquently convey the essence of each product.

Saving the Extracted Product Data
In the subsequent phase, we execute the functions to scrape Debenhams retail data, collecting and storing it within an empty list. Following this, we preserve this data as a CSV file.

We define an async function 'main' as the web scraping entry point. Using the async_playwright library, we launch a Firefox browser and create a new page. The base URL, representing Debenhams' women's wedding category, is then passed to the 'perform_request_with_retry' function to ensure web page access and handle potential retries.
We utilize the 'get_product_urls' function to gather all product URLs within the women's wedding category. These URLs are crucial for navigating individual product pages and extracting specific product data. As we iterate through each product URL, we invoke various functions, such as 'get_product_name,' 'get_brand_name,' etc., to extract detailed product information like name, brand, SKU, image URL, rating, number of reviews, MRP, sale price, discount percentage, color, description, and details and care information. These functions employ asynchronous techniques to interact with the respective web pages and retrieve information.
Hence, print the periodic updates on the number of processed links to monitor scraping progress. Finally, we store all extracted data in a pandas DataFrame and save it as a CSV file named "product_data.csv." In the 'main' section, we use asyncio.run(main()) to execute the primary function asynchronously, running the entire web scraping process and generating the CSV file.
Conclusion: To sum up, this Playwright Python guide offers a gateway to opportunities for individuals keen on scraping Debenhams' Women's Wedding Collections. Using Python libraries such as BeautifulSoup and Requests, we have embarked on a voyage that equips us to extract valuable data from the Debenhams website effortlessly.
Product Data Scrape is committed to upholding the utmost standards of ethical
conduct across our Competitor Price Monitoring Services and
Mobile App Data Scraping operations.
With a global presence across multiple offices, we meet our customers' diverse needs with
excellence and integrity.




































.webp)





