
Gap.com, the online storefront for Gap Inc., is a prominent player in the fashion industry, renowned for its diverse range of clothing and accessories. Its influence extends beyond its product offerings, as Gap often sets the standard in various aspects, including pricing and marketing strategies. Competitors frequently resort to data scraping tools to monitor Gap's inventory, using this information to glean valuable insights into market trends. Scrape Gap data to gather comprehensive product information, analyze market trends, and gain valuable insights into consumer preferences and shopping patterns.
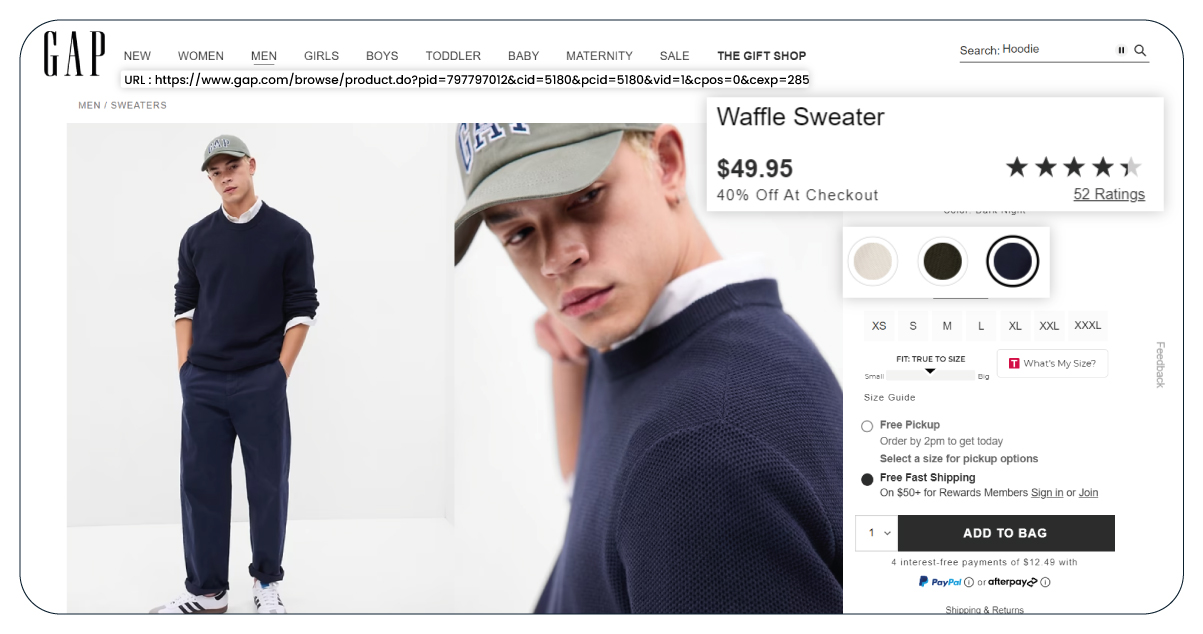
We regularly receive requests for data extraction from Gap.com. In this tutorial, we will guide you through scraping data from the 'Women’s Just Arrived’ category on Gap.com. This endeavor aims to shed light on the potential insights one can uncover. These insights encompass tracking the popularity of fashion items, analyzing pricing dynamics, and obtaining a deeper understanding of consumer preferences within the retail sector.
Reason to Choose Gap for Scraping
Product Data Scrape often finds itself drawn to Gap as a preferred source for web scraping. Gap.com offers a wealth of data that can help gain valuable insights, including:
Market Intelligence: Gap.com data enables a deep understanding of product trends, pricing strategies, promotional activities, and inventory levels in the fashion market.
Consumer Preferences: By scraping Gap.com, one can tap into customers' preferences, discerning which products hold the most appeal and staying attuned to the consumer's voice.
Trend Spotting: Gap.com data allows for the identification and anticipation of current and emerging market trends, giving businesses a competitive edge.
Pricing Analysis: A comprehensive analysis of product pricing strategies, encompassing the impact of discounts and other promotional tactics, becomes possible through Gap.com web scraping.
- Product URL
- Product Type
- Product Name
- Fabric and Care
- Selling Price
- Max Retail Price
- Rating
- Available Sizes
- Number of Ratings
- Color
- Fit
- Sizing
- Product Details
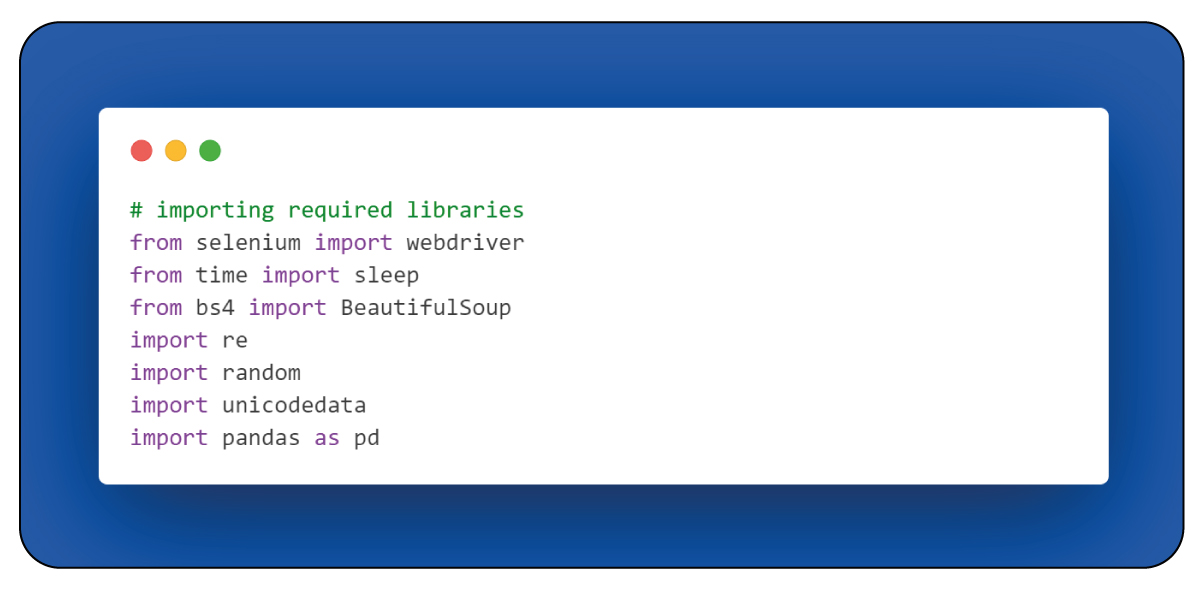
Import Necessary Libraries
We commence by importing essential Python libraries to scrape retail product data. These libraries serve diverse functions, ranging from managing web drivers for browser automation to storing data in a structured tabular format. Our program harnesses seven distinct libraries, each serving a unique and specialized role.
Detail Overview of Web Drivers
A WebDriver is a vital software tool that empowers you to control a web browser programmatically. These web drivers play a pivotal role in automating many tasks, including web scraping, automated testing of web applications, and various interactions with websites.
(a) Browser Interaction: Web drivers facilitate seamless interaction with popular web browsers like Google Chrome, Mozilla Firefox, Microsoft Edge, and others through code. They enable you to open and close web pages, navigate through websites, click on links and buttons, fill out forms, and extract data from web pages.
(b) Cross-Browser Compatibility: Many web drivers can work harmoniously with multiple web browsers. This cross-browser compatibility is crucial for thoroughly testing web applications across different browsers to ensure compatibility.
(c) Programming Languages: Web drivers are typically available in various programming languages, such as Python, Java, JavaScript, C#, and more. This broad language support makes them accessible to developers with diverse language preferences.
(d) Automation Frameworks: It integrates into comprehensive test automation frameworks like Selenium, WebDriverIO, Puppeteer, and Playwright. These frameworks offer higher-level abstractions and tools for efficient web automation.
(e) Headless Browsing: Some web drivers extend their support to headless browsing, enabling the operation of a browser without a graphical user interface. Headless browsers are particularly valuable for automated tasks where the visual browser window is unnecessary, but interaction with web pages remains essential.
Here are a few examples of well-known web drivers employed for web scraping, along with their associated libraries/frameworks:
Selenium WebDriver: Selenium is a widely recognized automation framework that accommodates multiple programming languages and browsers. Selenium WebDriver empowers you to automate web page interactions using various programming languages.
Puppeteer: This Node.js library is created by Google, primarily for monitoring Chrome or Chromium browsers. It is frequently helpful in web scraping and automated testing.
Playwright: Playwright is a relatively newer automation library developed by Microsoft. It boasts support for multiple browsers, including Chromium, Firefox, and WebKit. Like Puppeteer, Playwright is favored for browser automation and offers more versatility concerning browser support.
Web drivers have ushered in a new era of web scraping, serving as indispensable tools for professional web scraping services in building scrapers for platforms like Amazon and extracting data from various e-commerce websites.
Selenium Web Driver:
Selenium Web Driver is a fundamental tool for automating web browser interactions. It mimics human user actions, making it invaluable for automating tasks like website navigation, button clicking, and form filling. In web scraping, it's a crucial asset, particularly for dynamic websites that require element interactions. While we use the Chrome WebDriver in this program, alternative WebDrivers are available for different browsers.
Critical Uses of WebDriver in Web Scraping:
Scraping JavaScript-Protected Websites: WebDriver can extract data from websites safeguarded by JavaScript.
Handling User Authentication: It's apt for scraping sites demanding user authentication.
Automation Prowess: WebDriver excels at automating many web tasks, making it indispensable in web scraping and beyond.
Introducing Time Delays with Sleep ():
The sleep() function is a Python feature that introduces delays in program execution, pausing it for a specified duration. In web scraping, it proves helpful in spacing out requests to avoid overwhelming a website's server. Overloading a server with rapid-fire requests can lead to your IP blockage. The sleep() function also emulates human browsing behavior by adding delays between actions, making your web scraping script more discreet.
Beautiful Soup (bs4):
Beautiful Soup is a Python library tailored for parsing HTML and XML documents, creating a structured parse tree for data extraction. Widely embraced for web scraping, it stands out for its user-friendliness, rich feature set, speed, and extensive documentation. In web scraping, Beautiful Soup extracts data by parsing a website's HTML and locating the desired information.
Advantages of Beautiful Soup in Web Scraping:
- Ease of Use
- Versatility
- Efficiency
- Comprehensive Documentation
- Strong Community Support
In this tutorial, we will scrape Gap.com using Python to parse HTML content, opting for the lxml parser known for its speed and suitability for web scraping.
Regular Expressions (Regex):
Regular expressions, or regex, are potent tools for pattern matching and text manipulation. In Python, the built-in re module supports regex, offering capabilities like pattern finding, data extraction, text replacement, string splitting, and more. In web scraping, regex comes into play for tasks such as locating, extracting, validating, and cleaning data within HTML source code.
Utilizing Regular Expressions in Web Scraping:
- Locating Desired Data
- Extracting Data
- Validating Data
- Cleaning Data
Regex can be challenging to grasp, but it is a robust tool for automating diverse web scraping tasks.
The random Module:
Python's random module is an in-built library for generating random numbers. In our context, it's instrumental for introducing randomized delays between successive web requests, aiding in a more inconspicuous and efficient scraping process.
Unidecode:
Unidecode operates within the realm of Unicode, the character encoding system representing many characters from various writing systems. Unicode is the standard character encoding system used by modern computers. The Python Unicode data module grants access to the Unicode Character Database, enabling the handling of text encoding issues, removal of invisible characters, and text standardization.
Applications of Unidecode in Web Scraping:
- Resolving Text Encoding Discrepancies
- Eliminating Non-Breaking Spaces and Invisible Characters
- Standardizing Text
Unidecode proves indispensable in tackling text encoding issues, ensuring clean and interpretable data. This tutorial helps to regularize zero-width characters, which can otherwise complicate web scraping tasks.
Pandas:
Pandas is a Python library designed for efficiently handling and analyzing tabular data. This versatile tool offers high-performance data structures and a range of data manipulation functions, making it a popular choice for data cleaning, transformation, and analysis tasks.
DataFrame in Pandas:
The central data structure in Pandas is the DataFrame, which resembles a spreadsheet. It allows you to organize and manage data in a structured format with rows and columns. This tabular arrangement is ideal for various data-related tasks.
Web Scraping with DataFrames:
In the context of web scraping, DataFrames are invaluable for several purposes:
Storing Extracted Data:
You can use DataFrames to store data extracted from web pages. It enables you to organize the information neatly and access it conveniently.
Cleaning and Manipulating Data:
DataFrames are powerful tools for data cleaning and manipulation. You can easily filter, transform, and modify the extracted data to prepare it for further analysis.
Analyzing Data:
Data analysis becomes more manageable with DataFrames. You can perform statistical operations, aggregations, and calculations on the data within the tabular structure.
Exporting Data:
To save the processed data for later use or to share with others, Pandas provides the .to_csv() method. This method allows you to export a DataFrame to a CSV (Comma-Separated Values) file, a standard format for storing tabular data with rows and columns separated by commas.
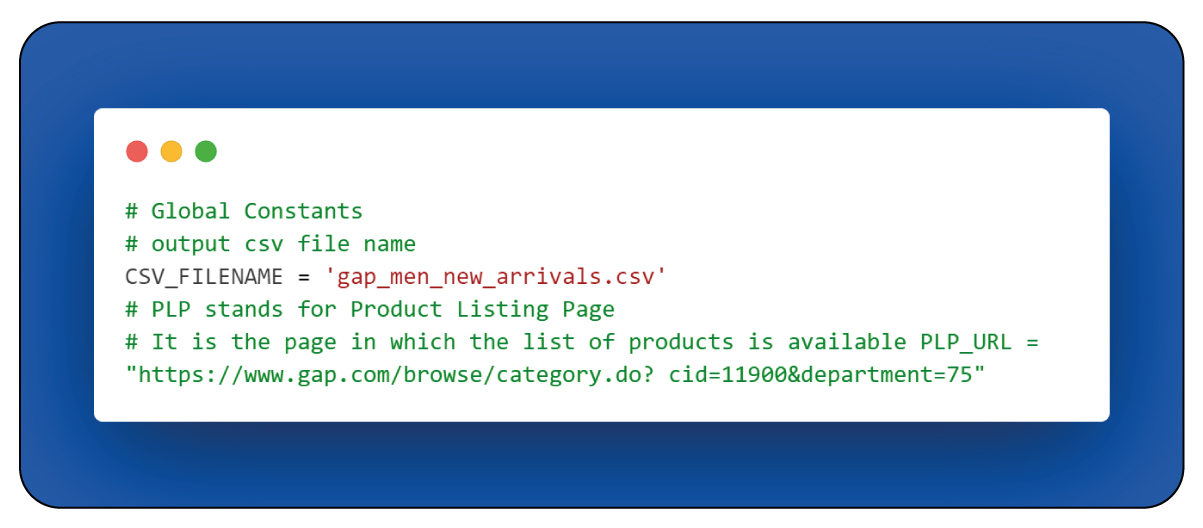
Global Constants:
Upon importing the necessary libraries, it establishes some global variables used throughout your script. These constants are defined at the script's outset, ensuring consistent usage and referencing specific values or configurations.
Initializing the WebDriver:
When dealing with dynamic websites like Gap.com, many elements become interactive only when interacted with. To overcome this challenge, our retail data scraping services employ Selenium to instantiate the Chrome WebDriver. This WebDriver serves as a tool to navigate the webpage and trigger the activation of each element.
The initialize_driver() function serves the purpose of creating a Chrome WebDriver instance, which is essential for web browser control.
Following the initialization, the Chrome WebDriver is assigned to a variable called "driver" via the initialize_driver above function.
After accomplishment, direct the driver to the designated destination, the "Men New Arrivals at Gap" web page.
To ensure that every element on the page is activated, a crucial step involves scrolling down the page continuously. This action is necessary because the web page operates with infinite scrolling, and reaching the genuine bottom of the page is essential to activate all elements.
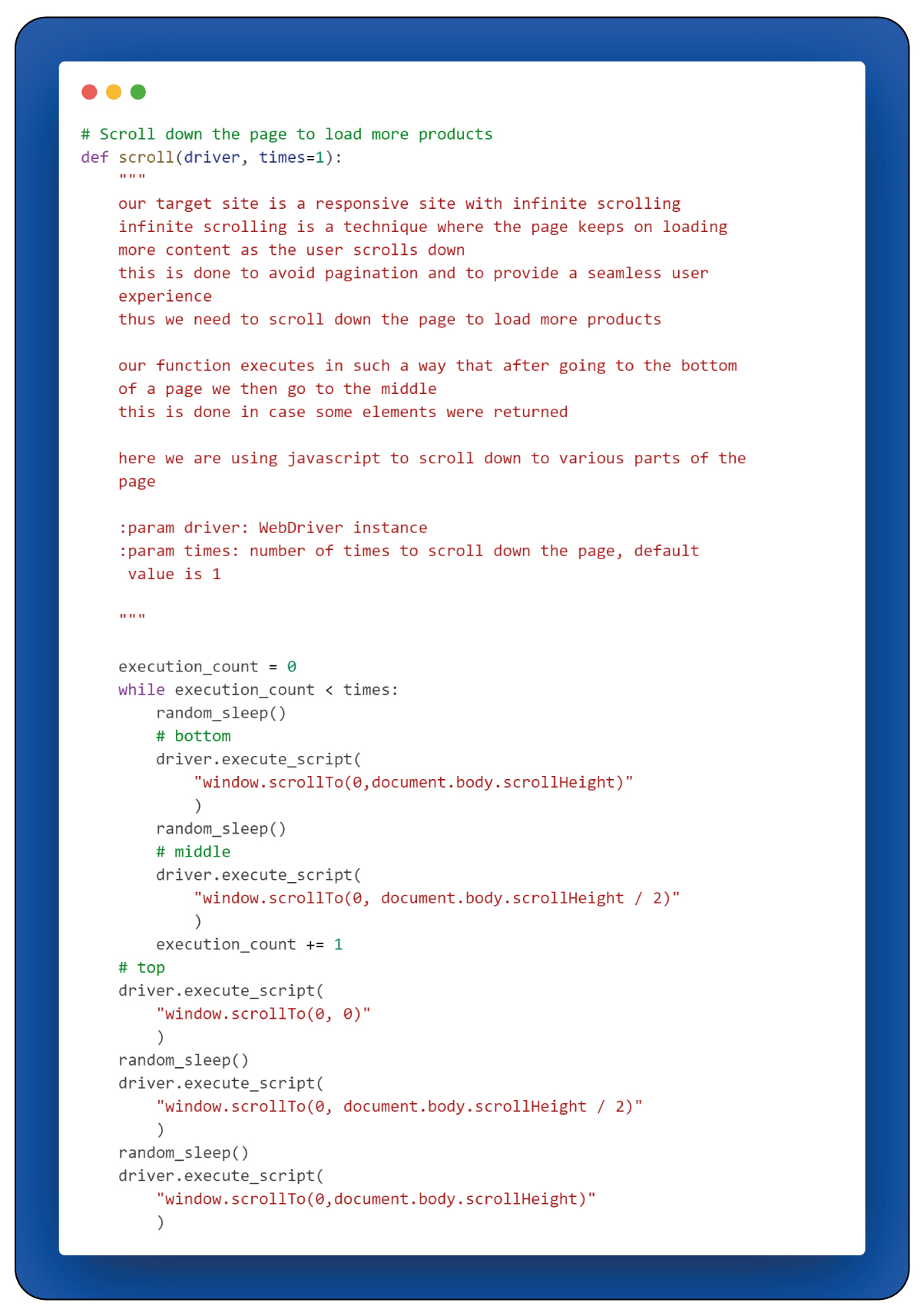
The scroll() function can replicate the process of scrolling down the webpage, which triggers the loading of additional products. In our case, the target site is a responsive webpage, and initially, not all products are loaded. These products only become visible and have their elements loaded when we scroll through or beyond them.
The scrolling action is performed multiple times, with the frequency of scrolling determined by the "times" parameter.
Random delays are incorporated to make the script's interactions closely resemble human behavior. These delays introduce a degree of unpredictability in the timing of actions, mirroring the natural variations in human interaction with a webpage.

The random_sleep() function leverages the random library to generate a random number from four (inclusive) to seven. This generated number is then employed to introduce a pause in the script's execution, equivalent to the duration of the obtained random number.
Selenium web drivers occasionally require additional time to load a web page entirely. To accommodate this potential variability, the random sleep function utilizes a range of four to seven seconds.
The script employs the "uniform" function from the random module, which yields decimal numbers rather than whole integers to simulate a more natural human-like behavior.
After activating the JavaScript components of the webpage, the BeautifulSoup library can parse the HTML source code of the webpage. Choose the "lxml" parser for this parsing task.
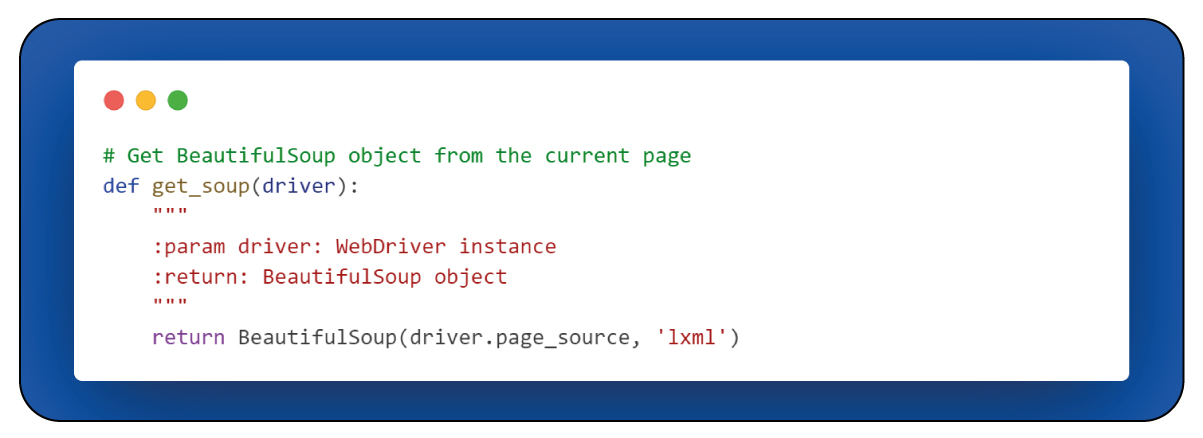
The get_soup() function serves the purpose of extracting a BeautifulSoup object from the HTML source of the provided web page. BeautifulSoup is a valuable library utilized for parsing and traversing the content of the HTML.
Main Program Flow:
This part of the program outlines the primary sequence of operations and executed functions to navigate and interact with the web page.
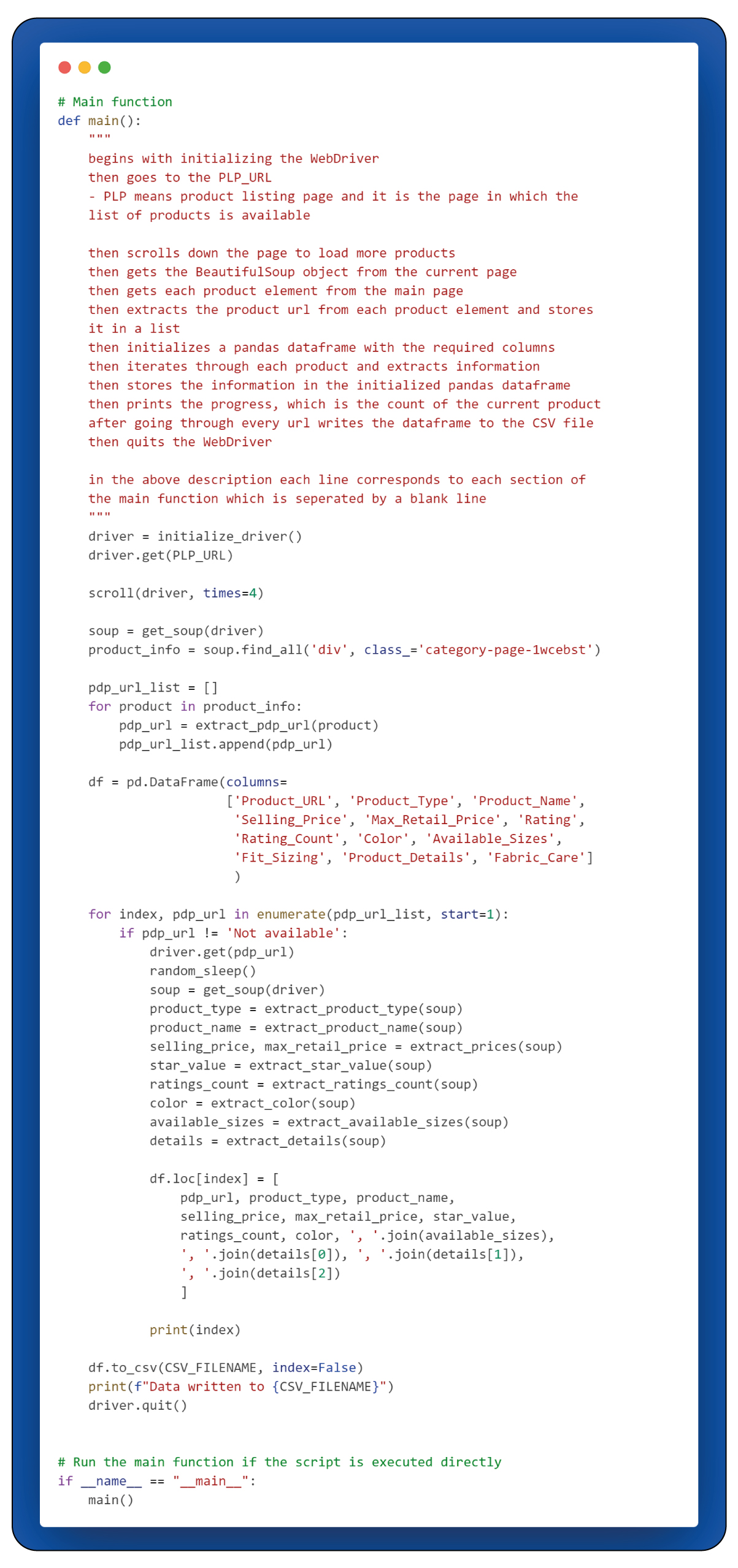
The main() function serves as the central location where the primary web scraping process unfolds, involving the invocation of all the predefined functions. Additionally, within the main() function, the extracted data is stored.
The script includes a check to determine if it is being executed directly or imported as a module. After executing directly, the main() function executes.
Categorize the main() function into three distinct parts, with the first part focusing on extracting Product Detail Page (PDP) URLs.
Main Program Flow – Extracting PDP URL:
This portion of the program outlines the steps and procedures for extracting Product Detail Page (PDP) URLs from the web page.
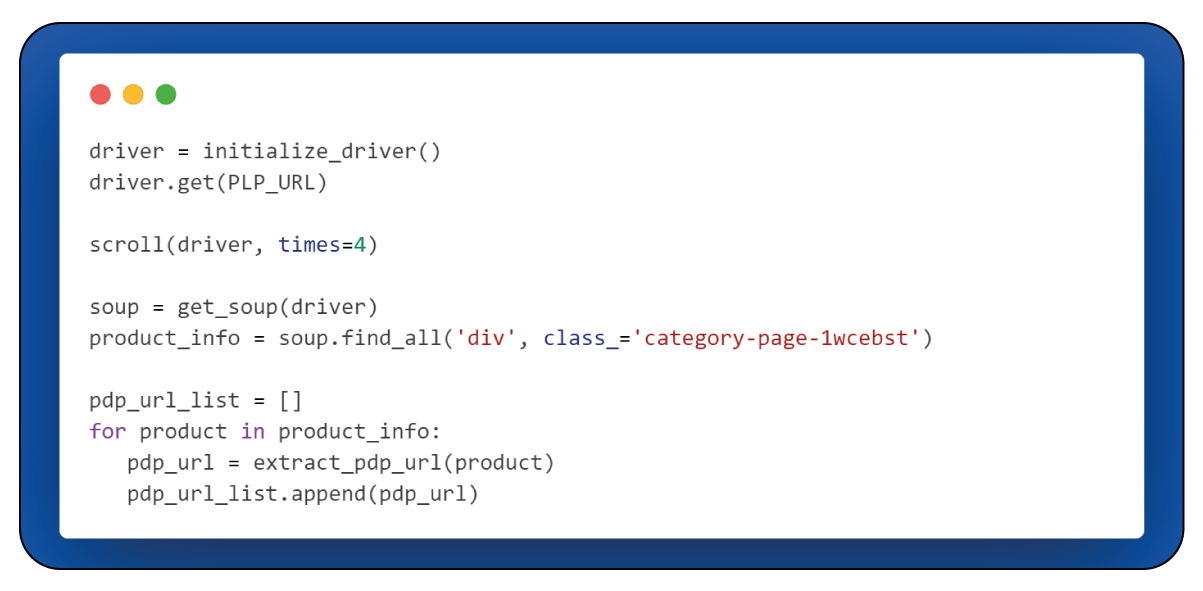
We initiate the process by using the PLP_URL to navigate to our intended target page, "Women Just Arrived at Gap." Upon reaching this target page, we observe currently 266 products available in the Women Just Arrived section. It's important to note that the specific count of products may vary with each batch of new arrivals.
Subsequently, we leverage the BeautifulSoup object to navigate the parsed HTML document and extract data. We aim to identify and isolate the "div" elements corresponding to all 266 products. These "div" elements serve as containers for product information and are available within a variable named "product_info."
A "div" element is a fundamental HTML element pivotal in structuring and formatting web content. The term "div" stands for "division," and it is applicable for grouping and organizing content on a web page.
The next step involves iterating through the "product_info" variable to extract the Product Description Page (PDP) URL for each product. PDP, which stands for "product description page," is the destination where comprehensive details about each product are available.
For efficiency and reference, the URLs of all 266 products are collected and stored in a list. This collection of URLs is gathered at the outset to facilitate easy access in case of any issues that may arise during subsequent stages.
Now, let's delve into the function responsible for extracting the PDP URL, denoted as "extract_pdp_url(product)."
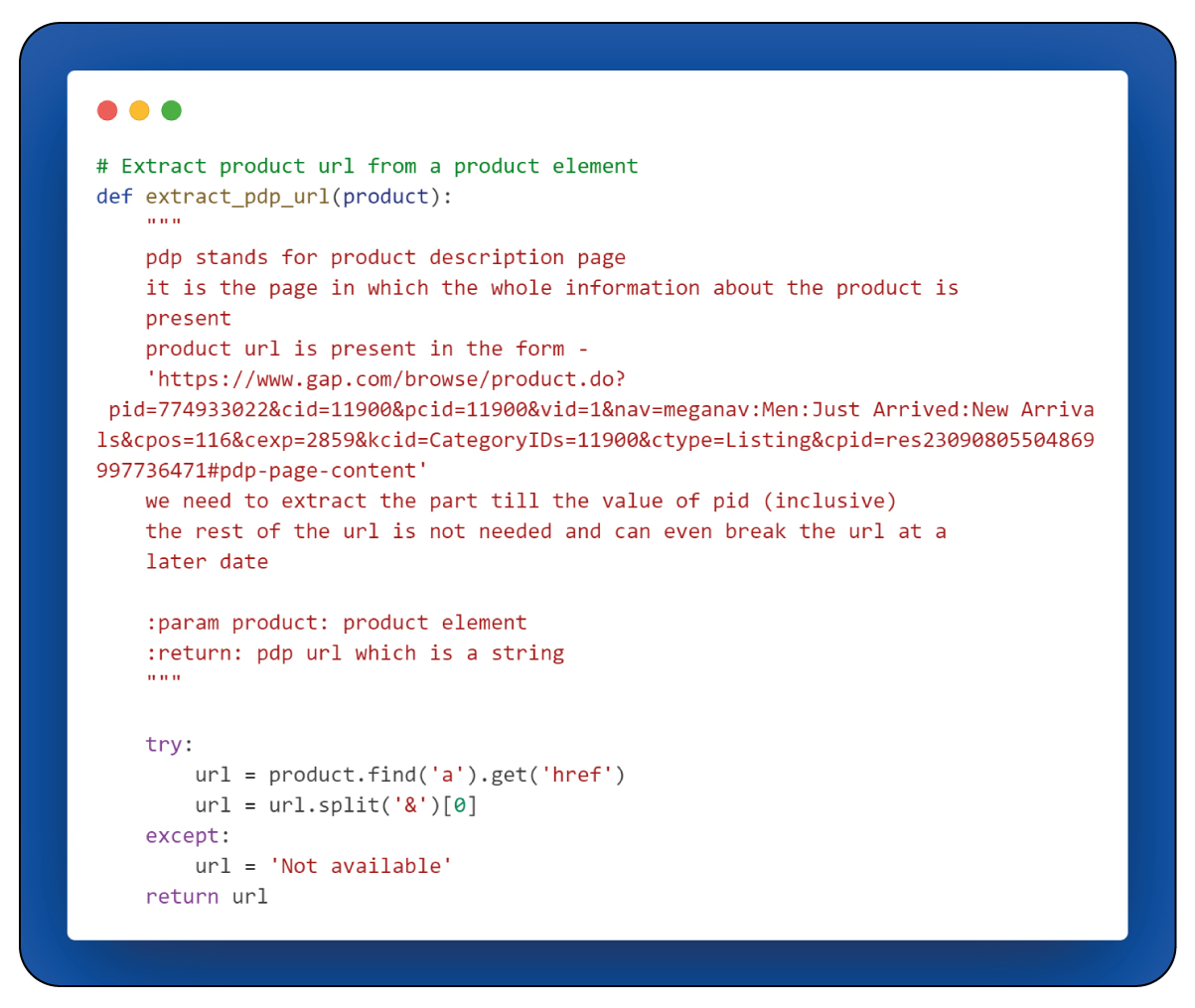
In the "extract_pdp_url(product)" function, it takes as input a product element, which is known as a < div > element with the class attribute "category-page-1wcebst." The primary goal of this function is to extract the URL of the product description page (PDP).
The function locates the < a > element within the provided < div > element. An < a > element is essentially an anchor element, often referred to as a hyperlink or link in web development. It is responsible for creating clickable links within web pages. When users interact with an < a > element, it typically redirects them to another web page or resource available in the "href" attribute.
The retail data scraper collects the URL by retrieving the value of the "href" attribute within the < a > element. However, the obtained URL may include unnecessary components at the end that could cause issues in the future. The function extracts only the part of the URL up to the "pid" value, ensuring that it remains functional and avoids any potential issues related to broken URLs.
Main Program Flow - Product Data Extraction:
This program section outlines the primary steps and procedures for extracting essential product data, including PDP URLs, as part of the broader web scraping process.

The process of product data extraction commences with an iterative loop through the PDP URL list. In each iteration, the PDP URL for a specific product is available from the list. Subsequently, the WebDriver (driver) navigates to the acquired URL to access the product's page.
The "get_soup" function is then employed, utilizing BeautifulSoup with the "XML" parser to parse the HTML source code of the product page. The resulting soup object is the foundation for extracting all the essential product information. Achieve this extraction by utilizing the predefined functions tailored to gather data about various aspects of the product.
Upon successfully extracting data, the program displays the product count for collected data.
Now, let's delve into the segment where data extraction occurs:
Extracting Product Information:
The script includes several distinct functions, each extracting specific information from the product pages. These functions can capture product types, names, prices, ratings, the count of ratings, available colors, sizes, and various additional product particulars. Here's a breakdown of each of these functions:
extract_product_type(soup):
This function focuses on extracting information related to the product type from the provided BeautifulSoup object (soup). It identifies and retrieves the product type, categorizing it within the broader context of the website's inventory.
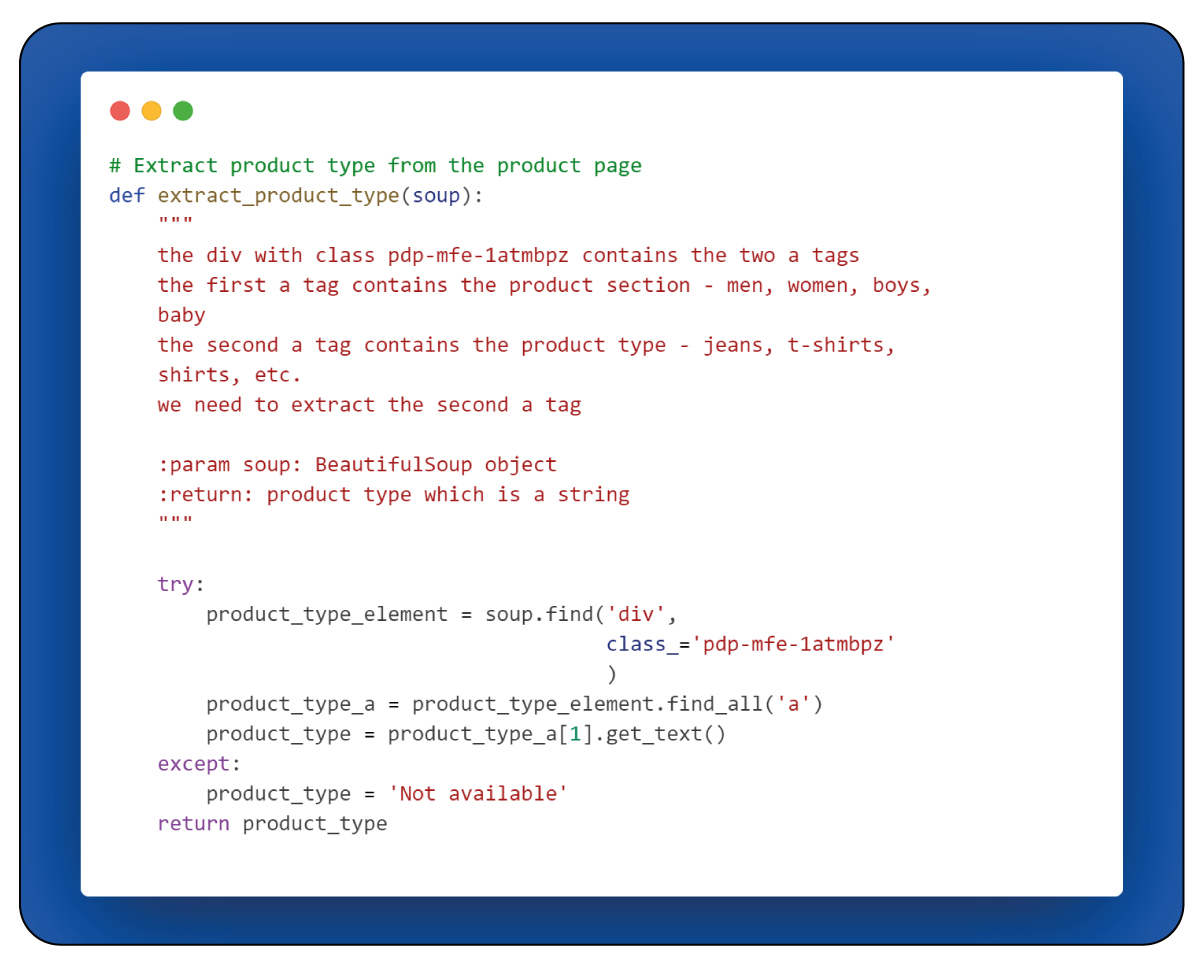
The "extract_product_type(soup)" function retrieves the product type from the product page. It achieves this by locating a specific < div > element characterized by the class attribute "pdp-mfe-1atmbpz" within the BeautifulSoup object (soup). The function then extracts the text contained within the second < a > element found inside this < div > element. This text typically corresponds to the product category or type, providing information about the nature of the examined product.
Next, let's explore the "extract_product_name(soup)" function, which is another crucial function for data extraction.
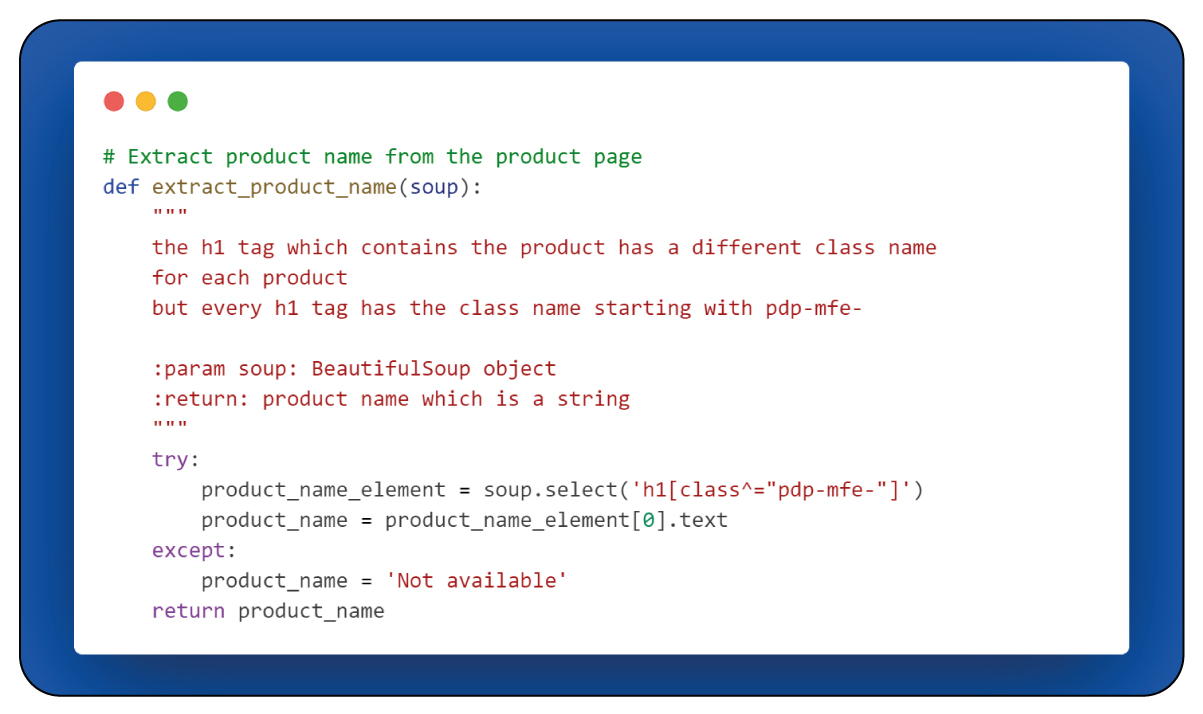
The "extract_product_name(soup)" function extracts the product's name from the product page. It accomplishes this by searching for an < h1 > element whose class attribute commences with "PDP-me-." Upon locating such an element, the function retrieves the text content. This text typically represents the product's name.
The rationale behind searching for elements having class attributes beginning with "pdp-mfe-" is that the different product names on their respective pages are within < h1 > elements with varying class names. The commonality among these class names is the "pdp-mfe-" prefix, the distinguishing factor.
Now, let's shift our focus to the "extract_prices(soup)" function, another integral component of the data extraction process.

The "extract_prices(soup)" function is responsible for extracting the product's pricing information, which includes both the selling price and the maximum retail price (MRP). This extraction is available by identifying elements on the product page that are pertinent to pricing and then capturing the pertinent text data.
This function can handle various scenarios, including cases where only a single price is available and cases where price ranges are specified. It adeptly extracts and manages pricing data in these diverse situations, ensuring the accurate retrieval of pricing information.
Moving on to the "extract_star_value(soup)" function, let's delve into its role in data extraction.
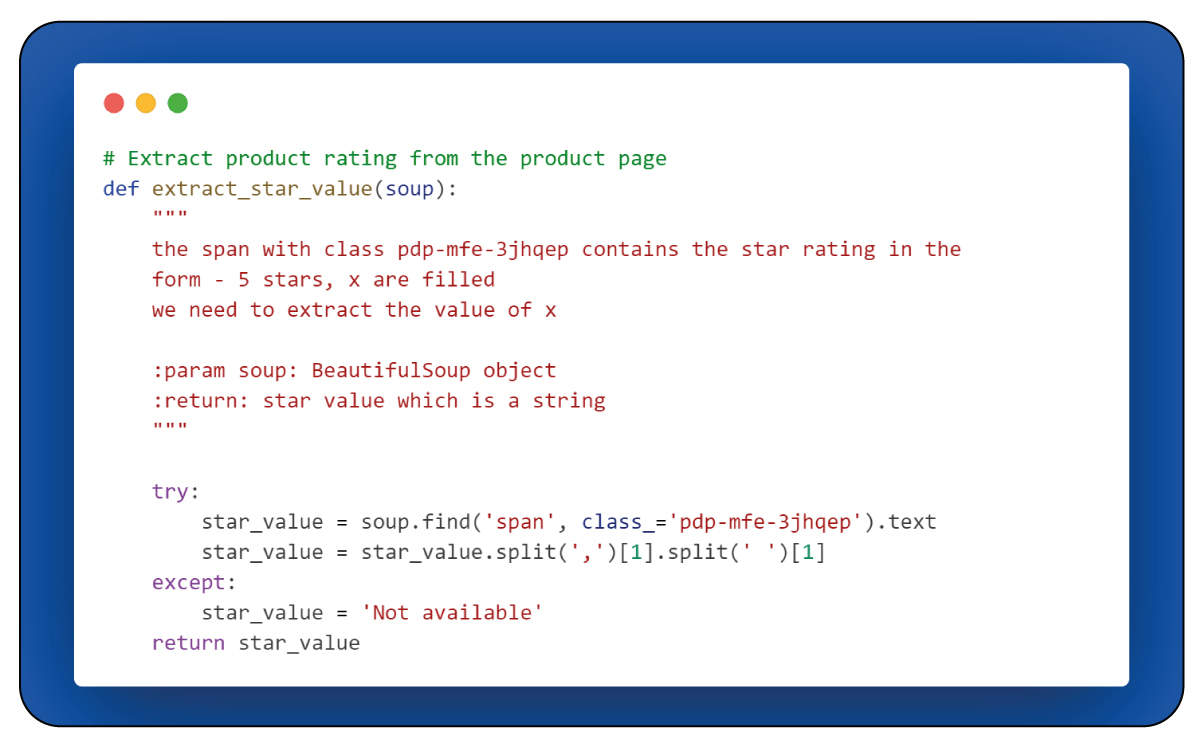
The "extract_star_value(soup)" function focuses on extracting the product's rating, specifically the average rating represented by the star count. To achieve this, the function searches for an element characterized by the class attribute "PDP-me-3jhqep," where the rating information is stored. It then extracts and refines the rating value from the text content within this element.
Now, let's focus on the "extract_rating_count(soup)" function and its role in the data extraction process.
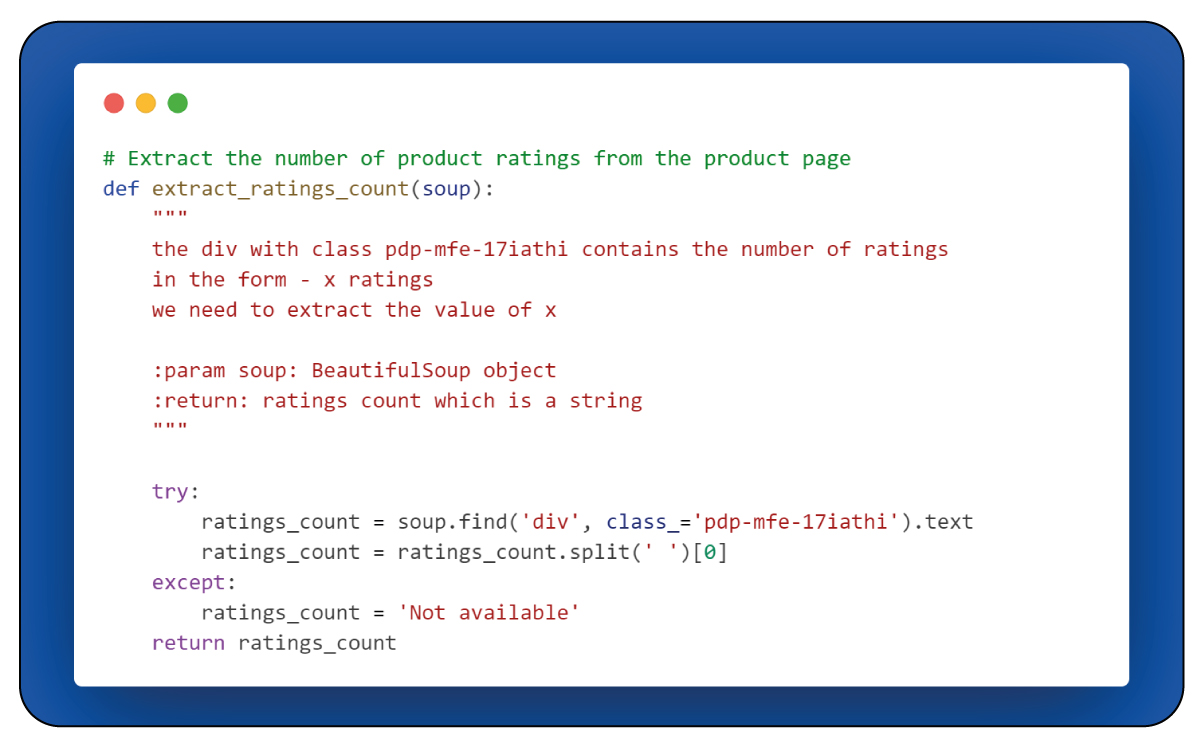
The "extract_rating_count(soup)" function can extract the count of product ratings from the product page. The function locates an
element with the class attribute "PDP-me-17iathi," within which the rating count information is available. The function then retrieves and captures the initial portion of the text within this specific
element, effectively obtaining the rating count.
Now, let's discuss the "extract_color(soup)" function and its purpose in the data extraction process.

Upon completing the data scraping process, store the gathered data in a CSV file. To facilitate this, initialize a pandas DataFrame and design a data structure for handling tabular data.

Add the data collected from each product page during each iteration to the initialized DataFrame within the same iteration.

Following the iteration through all 266 products, we write the DataFrame to a CSV file. After this, you will see a positive message, and the Chrome WebDriver instance is closed using the "driver.quit()" command.

Conclusion: For those interested in web scraping tools or APIs to gather product data from Gap, this script offers a valuable solution. The extracted data can be utilized for comprehensive analysis, providing insights into market trends and consumer preferences.
At Product Data Scrape, we uphold unwavering ethical standards in every facet of our operations, whether our Competitor Price Monitoring Services or Mobile App Data Scraping. With a worldwide footprint encompassing numerous offices, we steadfastly provide outstanding and transparent services to cater to the varied requirements of our esteemed clientele.




































.webp)





