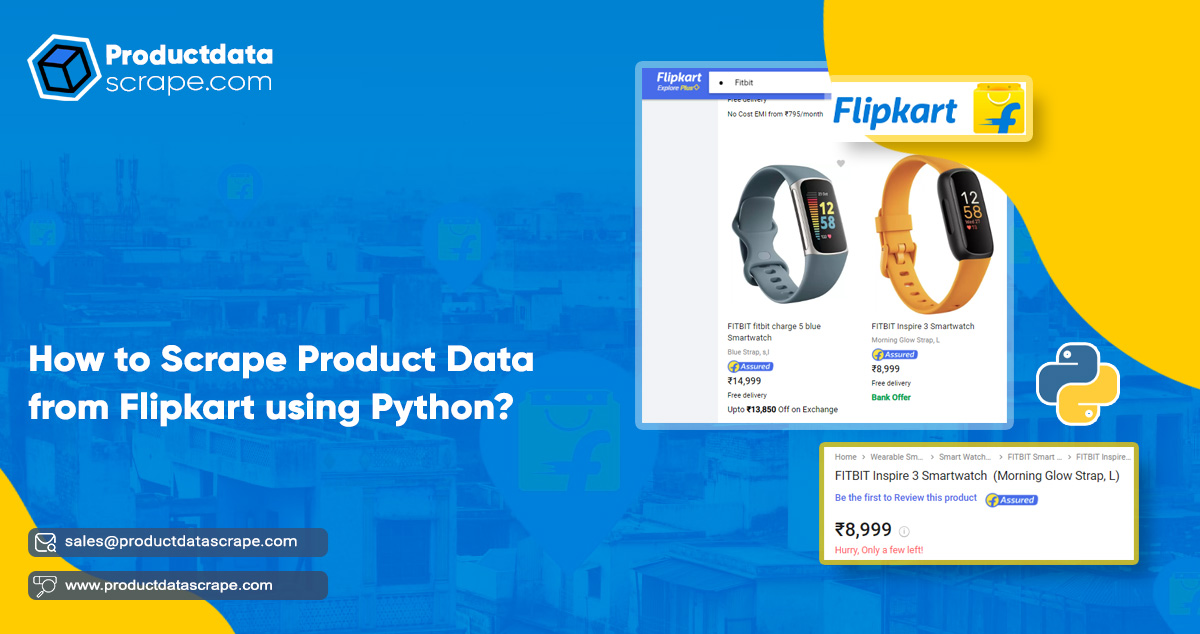
Flipkart is one of the top eCommerce platforms in India that offers courier services, online shopping, and bill payment options. It also comes under the biggest marketplaces category in the country, which supplies a broader product range to its users.
There is a huge volume of product data available on the Flipkart servers that attract marketers and marketing professionals to consider it as a treasure trove. Many brands and businesses find this data valuable and want to understand how their competitors are growing. This data's detailed study helps eCommerce businesses win more market share, accelerate their branding, increase brand image, maintain brand loyalty, and understand customers.
In this post, we'll share how to scrape product data from Flipkart using Python. We'll extract data for various smartwatches from the top Indian smartwatch companies and store the scraped data in CSV format.
The Brands
Before moving ahead with the process, let us inform you that we will scrape the smartwatch data for the following brands.
- Fitbit
- Apple
- Honor
- Garmin
- Samsung
- Noise
- Amazfit
- boAt
- Huawei
- Fossil
The Attributes
We are going to scrape the below product attributes for every smartwatch using Python.
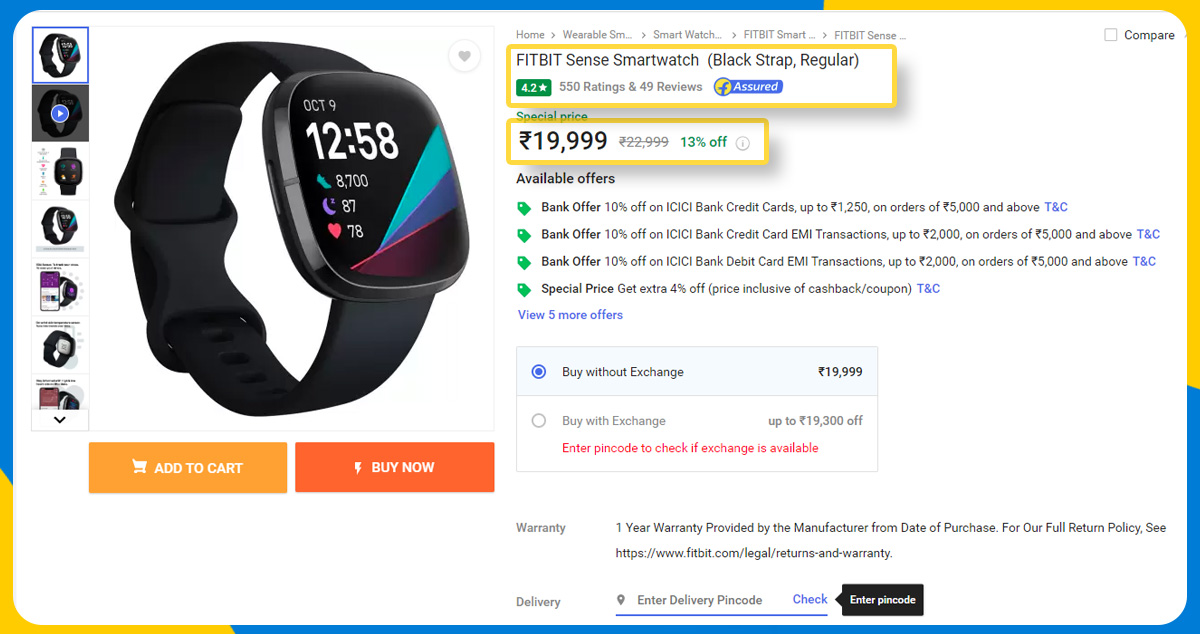
- Product URL - It is the product address of the specific product available on the web.
- Product Title - it is the product name on the Flipkart platform.
- Brand - It is a product brand like Huawei.
- Selling Price - This is a product price after applying a discount.
- MRP - It is the usual market price for the specific product.
- Discount Percentage - It is the percentage deduction from the product market price.
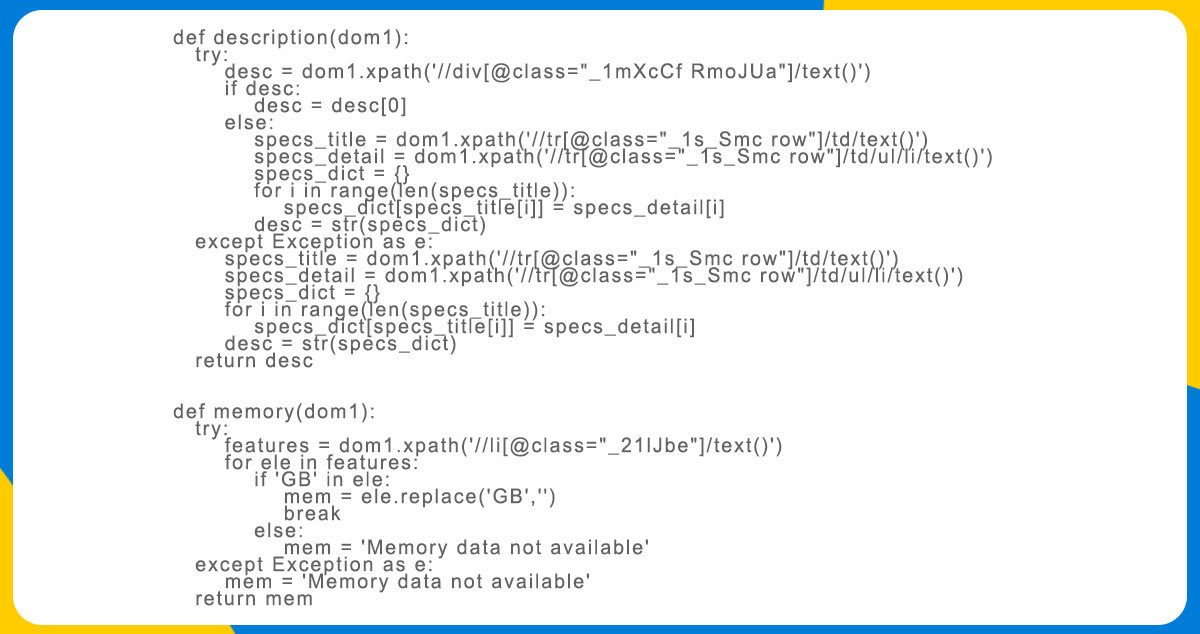
- Memory - It is the internal smartwatch memory.
- Rating Count - It is the total rating count that smartwatches receive from customers.
- Review Count - It is the total review count that customers wrote for a specific product.
- Star Rating - It is the overall product rating that customers give after using the product.
- Description - it is the short specifications or details for the product you can see on the product page on the Flipkart website.
What are the Required Libraries to Scrape Product Data from Flipkart Using Python?
Importing libraries is the primary step to scrape Flipkart product data using Python. In this project, we import requests, BeautifulSoup, CSV library, time library, random library, and etree module from the LXML library.

The BeautifulSoup library from Python parses and pulls product data from XML and HTML files.
The LXML library processes XML and HTML data, and etree or Elementtree parses XML documents.
The Requests Python library sends HTTP requests to servers.
The Random library generates numbers and randomizes the data scraping process in Python.
The CSV library reads and converts tabular information in the CSV format.
Time library represents time in multiple ways.
Now, it's time to go through the Flipkart data scraping process using Python.
Flipkart Data Scraping Process using Python
Once you import the necessary Python libraries, define the user agent header list in the next step. The user agent's string contains the text that the customer shares using a request to help the server recognize the web browser, operating system, and device type that you're using to perform the scraping process.
Many eCommerce websites block data Scrapers as they don't want to share product data from their platform with bots or automated data scrapers. To avoid Blocking from the source website, you must define a user agent to make requests. The web server may recognize and block your user agent using a single user-agent header. To avoid this, you should keep rotating the user agent. It will signal to the web server that a different user agent is requesting from different web browsers.

In the above code block, you can observe that we've designated a user agent list, namely header_list, and passed three headers of user agents in it. Further, we've initiated two more lists, namely smartWarch_brands, and product_list. These lists contain brands of watches and black places to store product URLs, respectively. We will also use the base_url string later in the process that we have also initiated.
Then we go through every operation during Scraping the specific product link.

While scraping data from the targeted website, the URL is the first requirement. Using the for loop, we collect every smartwatch brand from the string smartWatch_brands and concatenate it with the string to save in the page_url variable. It consists of the link to the first web page for the specific smartwatch category from the source. Now, it's time to call the function get_dom() and pass the parameter as page_url.

We randomly choose the user agent header in the get_dom function from header_list and pass it to the user_agenr as the value. Later, we send the HTTP request to the webpage UTL we wish to access using a user-agent like a header. We use the Requests library from Python to send this request. It reflects the response object that includes the response of the server. The server response contains the HTML content of the source website, and it stores it in the response variable. This HTML content is hard to parse due to its raw form. Hence, to ease traversing, we will transform that raw HTML content format into the parse tree with the help of a parser. BeautifulSoup library will help us to achieve this with the etree module of the LXML library, where we will convert the raw HTML content in the tree structure. Python libraries will return and store the tree structure in the dom various inside the loop.
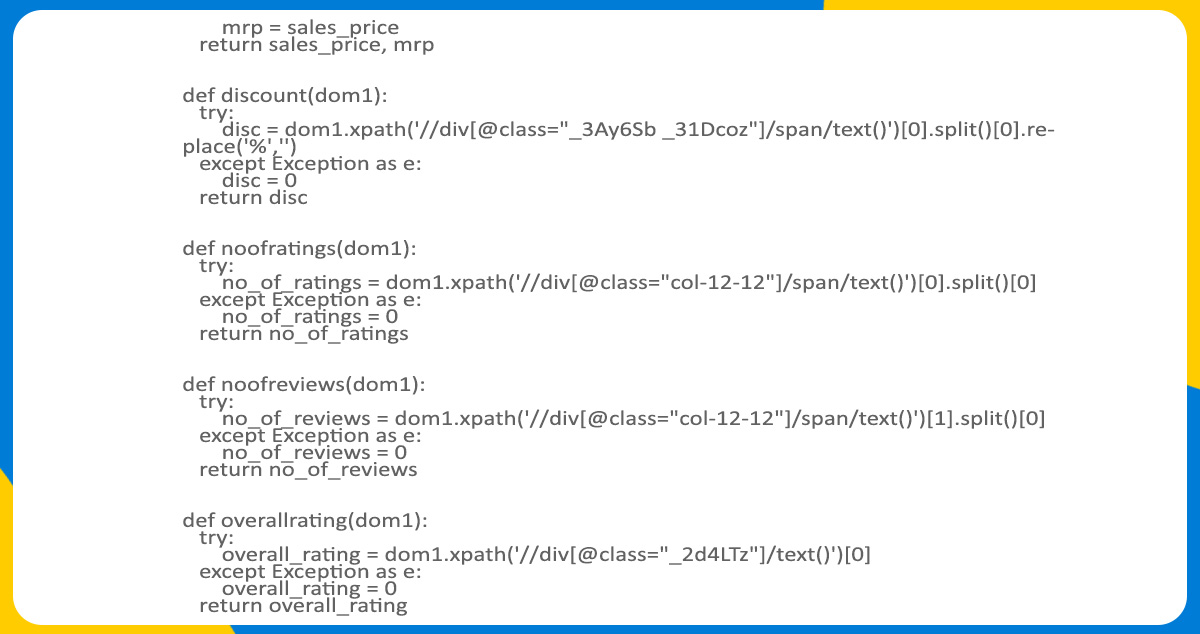
We will use XPath in the next step to store various elements we plan to collect from the website. To do this, we will choose the element from the website to extract and inspect it by right-clicking on the mouse. By doing this, we will get the class name and tag where we can see the enclosed elements. We will use the class and tag name to get the element out from the XPath. Check the below example of scraping an element using XPath.
We can observe the product link enclosed inside the anchor tag and _1fQZEK class. We retrieved the URL for this product using the following code line.

This code line in the program will save the URLs of each product listed on the page with the list, namely page_product_list. We will add this list to the product _list, which contains all the URLs of smartwatches with brands from the smartWatch_brands list. Lastly, we gave a time delay with the help of the time library to bypass the blocking from the source while scraping.
Writing the Data to a CSV File
After extracting the data, we should save it for future use for various requirements like market research, competitor analysis, price monitoring, and more. Let's understand how to write the collected data to the CSV file.
Open the comma-separated value file smartwatch_data.csv in f as the write mode. Then make a writer object, namely theWriter, and initiate the heading list containing every data column. After this, write to the CSV file using the below writerow() function.

Once we write the heading in the file, we will iterate through all the products from the list. The URLs in the product _link don't have a Flipkart domain name. Hence, we will concatenate the Flipkart domain name to it using the base_url we initially defined and pass this URL as the function parameter. Every function retrieves separate product attributes and reflects them. We store these values in the record list. Later, we will write product details as the next two inside the CSV file using the function writerow(record).
Conclusion
In this way, we explored how to scrape product data from Flipkart using Python and various Python libraries for one of our project in Flipkart Data Scraping Services. Here we scraped smartwatch data. But by making some changes in the code, you can scrape any product category with customization from Flipkart using Python with the help of our Flipkart product data extraction services.
At Product Data Scrape, we help with eCommerce data scraping services, product matching, retail analytics, competitor monitoring, market research, and more. If you want any help, contact Product Data Scrape.





































.webp)





