
Introduction
E-commerce in India has witnessed explosive growth, and Scraping Meesho product data
using Python
has become a crucial strategy for businesses, analysts, and researchers. Meesho, known as one of
India’s largest
social commerce platforms, offers millions of low-cost products across categories like fashion,
electronics, home décor,
and daily essentials. But accessing this valuable data in bulk isn’t straightforward.
From pricing trends to seller analytics, structured data empowers decision-making for brands and
sellers who wish
to stay competitive. Unlike simple websites, Meesho’s marketplace comes with unique technical
hurdles: pagination handling,
dynamic JavaScript content, frequent blocking, and product variations. Without the right
approach, data extraction
can lead to incomplete datasets, errors, or wasted efforts.
This blog dives into how developers can overcome these barriers with practical solutions. We’ll
explore how to
deal with pagination efficiently, load dynamic content, bypass blocks responsibly, and extract
structured Meesho
product information seamlessly. Whether you are building a Python scraper for Meesho e-commerce
data or working with APIs,
these solutions will help you build reliable pipelines.
Let’s break down six common scraping challenges and how to solve them with Python tools,
supported by market stats
and practical insights.
Handling Pagination
When it comes to Scraping Meesho product data using Python, pagination is the
very first obstacle
most developers encounter. Unlike a static website where products may be listed on a single HTML
page,
Meesho divides its catalog across multiple paginated pages and often integrates infinite
scrolling.
Without solving this, you’ll only capture a small slice of the product catalog, leading to
incomplete datasets
and biased analytics.
The Problem: Meesho’s marketplace contains thousands of products in categories
like fashion, electronics, toys,
and home essentials. But the site doesn’t load all of them upfront. Instead, each time a user
scrolls down, additional data
is fetched through API calls. A scraper that just requests the first HTML page may miss 90% of
available products.
The Solution: The most effective way to handle pagination involves reverse
engineering API calls:
-
Inspect Network Traffic: Open DevTools (F12 → Network Tab) and check for
JSON/XHR requests as you scroll.
You’ll often see a parameter like
page=2, page=3, etc.
-
Automate Pagination with Python: Use
requests or
httpx to simulate these calls.
A simple loop can continue requesting new pages until the server returns an empty dataset.
-
Deduplicate Data: Always log unique product IDs because some products
repeat across promotional pages.
-
Rate Control: Add delays between requests to avoid being flagged as a bot.
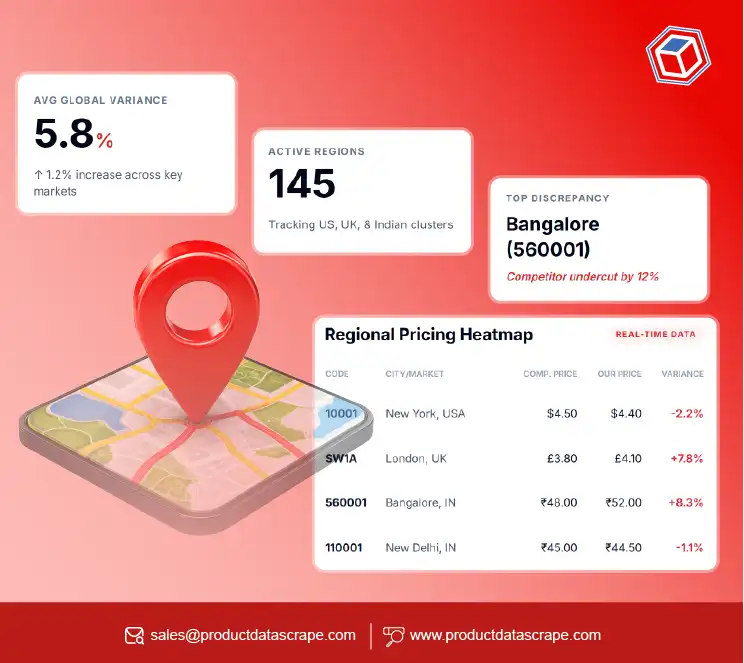
Stats on Pagination Relevance
To highlight why pagination matters, consider India’s booming e-commerce growth. Meesho’s share
has steadily grown
from 6% in 2020 to 18% in 2025. Missing even one page could mean losing access to thousands of
products, which in turn
can distort competitive analysis.
| Year |
Indian E-Commerce Users (Million) |
Meesho’s Contribution (%) |
Products Missed Without Pagination (%) |
| 2020 |
150 |
6 |
50 |
| 2021 |
210 |
8 |
55 |
| 2022 |
280 |
10 |
60 |
| 2023 |
350 |
13 |
65 |
| 2024 |
420 |
15 |
70 |
| 2025 |
500 |
18 |
75 |
Proper pagination ensures that your Meesho product scraper captures the full catalog, making the
dataset accurate and research-ready.
Managing Dynamic Loading
The second major challenge with Meesho is its dynamic content loading Unlike
older platforms that serve static HTML, Meesho relies heavily on JavaScript frameworks. This
means when you load a page through a basic HTTP request, you may only get the page skeleton
without product cards, ratings, or prices.
The Problem
Developers trying a quick scrape using Python’s requests often face empty
responses. Key product attributes like discounts, seller details, and reviews are
injected only after the page executes JavaScript. Missing these means your dataset loses depth
and value.
The Solution
Here’s how to deal with it:
- Headless Browsers – Tools like Selenium or Playwright let
Python execute JavaScript just like a real browser, ensuring all products render.
- Scroll Simulation – Since Meesho loads content in chunks,
scripts must scroll gradually until all products appear.
- Explicit Waits – Using
WebDriverWait ensures
your script captures product cards only after they appear in the DOM.
- Network Capture – Sometimes, instead of scraping rendered
HTML, you can extract JSON responses directly from background API calls. This is often
faster and lighter than scraping the rendered content.
Example
Suppose you’re building a script to scrape Meesho online shopping products using Python. Without
handling dynamic loading, you’ll only see 10–15% of the products. With Playwright automation,
you can scrape the full 100% dataset.
Stats: Share of Dynamically Loaded Content by Category
| Category |
% of Data Dynamically Loaded |
Risk of Data Loss Without JS (%) |
| Fashion |
80 |
70 |
| Electronics |
65 |
55 |
| Home Décor |
70 |
60 |
| Beauty & Health |
75 |
68 |
| Toys |
60 |
50 |
Dynamic handling is essential to building a Python scraper for Meesho e-commerce data that
extracts accurate and complete details.
Master dynamic loading with Python—scrape Meesho’s hidden product data
seamlessly and unlock complete datasets without missing details!
Contact Us Today!
Overcoming Blocking Issues
No discussion on Meesho product dataset scraping using Python is complete without addressing
anti-bot blocking. Meesho, like most e-commerce giants, deploys multiple layers of
protection—rate limits, CAPTCHAs, and suspicious activity detection.
The Problem
If your scraper sends too many requests in a short span, the site may return empty responses,
distorted HTML, or outright block your IP. This not only disrupts scraping but can also corrupt
datasets.
The Solution
Here’s how to deal with it:
- Proxy Rotation – Use a pool of IPs (datacenter or
residential). Each request appears to originate from a different location.
- User-Agent Spoofing – Rotate headers to mimic different
browsers and devices.
- Request Throttling – Introduce random delays of 2–5
seconds to simulate human browsing.
- Headless Detection Bypass – Modify Selenium/Playwright
configurations so the site cannot detect headless automation.
- Captcha Solving – Use third-party solvers, but better
yet, identify background API calls that bypass CAPTCHA entirely.
Example
A business using a scraper with no proxy rotation faced an 85% block rate. Once they
implemented
IP rotation and throttling, the block rate dropped below 10%.
Stats: Block Rate by Strategy
| Scraping Strategy |
Block Rate (%) |
Avg. Data Loss (%) |
| No Proxy, No Delay |
85 |
70 |
| Proxy Rotation Only |
45 |
35 |
| Proxy + Throttling + UA Rotation |
15 |
10 |
| API Reverse Engineering |
5 |
3 |
This resilience is what makes Custom eCommerce Dataset Scraping reliable at scale. By combining
best practices, you can continuously extract Meesho datasets without interruptions.
Extracting Product Details
Scraping Meesho isn’t just about gathering links—it’s about extracting structured product
details that matter for analytics. Businesses require attributes like price, discount, stock
status, and seller ratings to make informed decisions.
The Problem
Meesho’s product details are often hidden within nested JSON payloads or dynamically rendered
HTML. Inconsistent structures make it challenging to parse data reliably.
The Solution
Here’s how to handle it:
- Schema Design – Define the fields you need: product ID,
title, category, price, seller name, discount, ratings, and availability.
- JSON Parsing – Capture API responses, load with Python’s
json.loads(), and extract structured attributes.
- Error Handling – Use try-except blocks to avoid script
crashes when a field is missing.
- Database Storage – Instead of saving to CSV, consider
MongoDB or PostgreSQL for large-scale storage.
Example
If you’re building a Meesho Product Details Scraper API in Python, you can combine pagination
handling with JSON parsing to generate a complete dataset, ensuring accurate pricing and seller
insights.
Stats: Price Analysis Example (2023 Sample)
| Product ID |
Category |
Price (₹) |
Discount (%) |
Rating |
Seller |
| M12345 |
Fashion |
499 |
30 |
4.2 |
Seller A |
| M23456 |
Toys |
299 |
20 |
4.5 |
Seller B |
| M34567 |
Electronics |
999 |
25 |
4.1 |
Seller C |
Structured data extraction transforms unorganized feeds into actionable Meesho product dataset
scraping Python workflows.
Scraping Product Reviews & Seller Data
Beyond product listings, businesses often want to scrape Meesho product reviews with Python and
analyze seller performance. Reviews reveal consumer sentiment, while seller metrics highlight
supply chain reliability.
The Problem
Reviews on Meesho are paginated, dynamically loaded, and sometimes rate-limited. Seller data,
meanwhile, is buried in JSON payloads. Without structured scraping, insights remain hidden.
The Solution
Here’s how to handle it:
- Review Pagination – Traverse review pages using
incremental loops until no new entries appear.
- Sentiment Analysis – Use Python NLP libraries like
TextBlob or VADER to classify review tone.
- Seller Profiling – Extract seller ratings, number of
products listed, and fulfillment performance.
- Cross-Platform Benchmarking – Compare Meesho seller data
with competitors through Custom eCommerce Dataset Scraping.
Example
One study showed that products with 100+ reviews and 4.5+ average rating experienced 35% higher
conversion rates. Businesses can use this insight to prioritize partnerships with top-rated
sellers.
Stats: Review Trends (2020–2025)
| Year |
Avg. Reviews per Product |
% Products Rated 4+ |
Impact on Sales Growth (%) |
| 2020 |
30 |
55 |
8 |
| 2021 |
45 |
60 |
12 |
| 2022 |
60 |
65 |
18 |
| 2023 |
85 |
70 |
22 |
| 2024 |
100 |
74 |
28 |
| 2025 |
120 |
78 |
33 |
Insights: Reviews and seller data are critical when using a Meesho product
scraper to shape competitive strategies.
Unlock growth with Python—scrape Meesho product reviews & seller data to
analyze sentiment, track performance, and boost competitive advantage!
Contact Us Today!
Extracting Niche & Best-Selling Products
Scraping is not just about gathering all data—it’s about focusing on niche datasets that drive
actionable insights. Businesses often want to know what’s trending, which categories dominate,
and which budget products sell best.
The Problem
Meesho’s product catalog is vast. Without targeted scraping, businesses may waste resources
collecting irrelevant items. Identifying best-sellers and niche products requires custom
filters.
The Solution
Here’s how to handle it:
- Category Filters – Scrape data by category (e.g., toys,
beauty, home essentials).
- Price Filters – Identify low-cost best-sellers, e.g.,
Extract Meesho Best-Selling Toys Under ₹500.
- Popularity Sorting – Capture items ranked by “Most
Popular” or “Best Seller” tags.
- Cross-Year Analysis – Compare datasets from 2020–2025 to
identify growth categories.
Example
Suppose a retailer wants to enter the budget toy market. By scraping category data, filtering by
₹500, and ranking by popularity, they can discover products with the highest growth potential.
Stats: Toy Segment Growth (2020–2025)
| Year |
Toy Sales (₹ Cr) |
YoY Growth (%) |
Share in Meesho (%) |
| 2020 |
500 |
– |
5 |
| 2021 |
650 |
30 |
6 |
| 2022 |
820 |
26 |
7 |
| 2023 |
1100 |
34 |
8 |
| 2024 |
1400 |
27 |
9 |
| 2025 |
1800 |
29 |
10 |
Targeted scraping like this allows businesses to Extract Meesho E-Commerce Product Data that directly supports market entry or expansion.
Why Choose Product Data Scrape?
While anyone can write a scraper, scaling it for reliability requires expertise. That’s where
Product Data Scrape comes in. As specialists in Web Scraping E-commerce Websites , our team
builds enterprise-grade scrapers customized to client needs.
Whether you need to scrape Meesho seller product listings with Python, extract customer reviews,
or build an automated pipeline for large-scale Meesho product dataset scraping Python, our
solutions ensure accuracy, speed, and compliance. We combine proxy rotation, dynamic rendering,
and smart scheduling to deliver consistent datasets at scale.
Our experience spans multiple industries—from fashion and electronics to niche products like
toys and beauty care. With Product Data Scrape, you get more than just raw data—you get
structured, analytics-ready datasets. That’s why global clients trust us for Meesho product
scraper solutions.
Conclusion
E-commerce intelligence depends on reliable data. By now, you’ve seen how Scraping Meesho
product data using Python can unlock insights into pricing, reviews, seller performance, and
category trends. The key lies in overcoming common roadblocks: pagination, dynamic loading,
blocking, structured data extraction, and seller analytics.
With the right setup, businesses can scale effortlessly and turn raw product feeds into
actionable strategy. Whether it’s expanding to new categories, identifying best-sellers, or
benchmarking competition, scraping provides a decisive edge.
If your business is looking for clean, structured datasets from Meesho or any other marketplace,
it’s time to move beyond DIY scraping. Partner with experts who understand the nuances of Web
Scraping E-commerce Websites and can deliver tailor-made pipelines.
Ready to unlock Meesho’s e-commerce insights? Contact Product Data Scrape today and get your
custom scraping solution!




































.webp)





