
In today's digital age, the restaurant industry is experiencing a profound shift towards online platforms, where consumers increasingly rely on services like restaurant data scraping to access comprehensive information about dining establishments and their menus. Restaurant data scraping services have emerged as invaluable tools, enabling users to extract and analyze data from various online sources with precision and efficiency.
Scraping restaurant and menu data involves leveraging advanced techniques to collect pertinent information from restaurant websites, review platforms, and food delivery apps. It includes restaurant names, locations, cuisines, ratings, reviews, and, most importantly, menu items with their respective prices and descriptions.
These data scraping services offer numerous benefits for both consumers and businesses alike. For consumers, scraping restaurant data provides access to a wealth of information, allowing them to explore dining options, compare menus and prices, and make informed decisions about where to dine. For businesses, scraping menu data facilitates competitive analysis, market research, and strategic decision-making, empowering them to optimize menu offerings, pricing, and marketing strategies to better cater to consumer preferences and enhance their competitive edge. Scraping restaurant and menu data from Noon aids in making informed dining decisions and optimizing business strategies
By harnessing the power of restaurant data scraping services, stakeholders in the restaurant industry can unlock a treasure trove of insights, driving innovation and delivering exceptional dining experiences to customers.
List of Data Fields
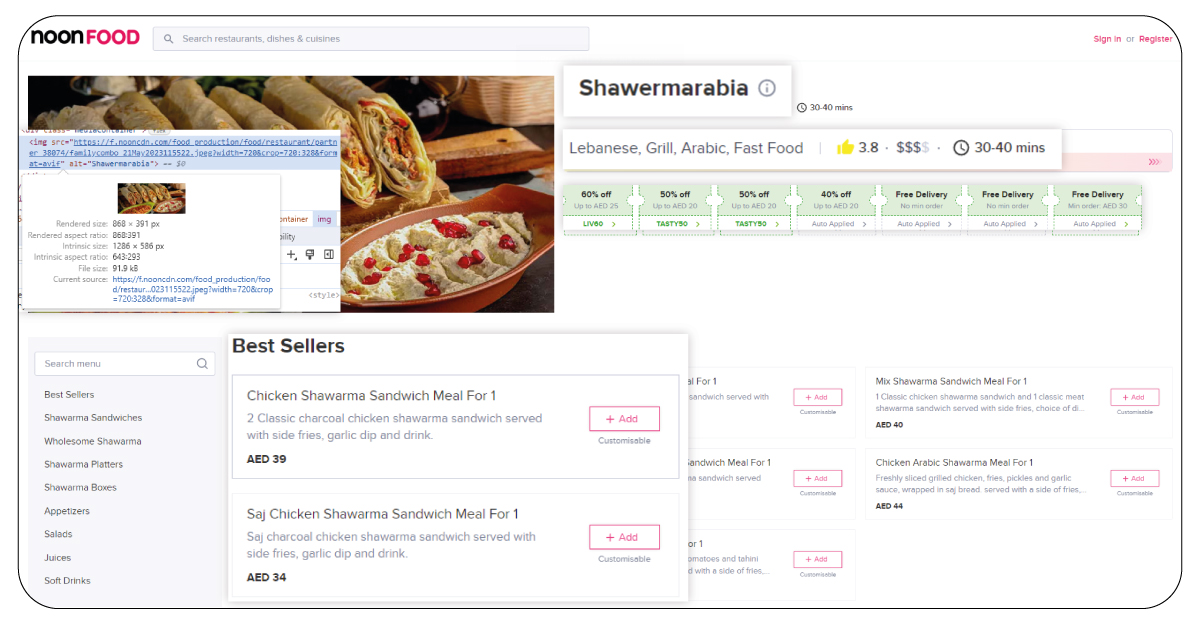
- Restaurant Name: The name of the dining establishment.
- Location: The address, city, state, and zip code of the restaurant.
- Cuisine Type: The cuisine served at the restaurant (e.g., Italian, Mexican, Asian).
- Ratings and Reviews: Customer ratings and reviews from reviews like Yelp or Google.
- Operating Hours: The hours of operation for the restaurant, including opening and closing times.
- Contact Information: The restaurant's phone number, email address, and website URL.
- Menu Items: A list of dishes and beverages offered on the menu.
- Menu Descriptions: Descriptions of menu items, including ingredients and preparation methods.
- Prices: The prices of menu items, including individual dish prices and combo meal prices.
- Dietary Information: Information about dietary options, such as vegetarian, vegan, gluten-free, or allergen-friendly dishes.
- Specials and Promotions: Any special offers, promotions, or discounts available at the restaurant.
- Images: Photos of the restaurant's interior, exterior, and menu items.
About Noon
Noon is a leading online platform that revolutionizes dining experiences by offering a diverse selection of restaurants and menus accessible with a few clicks. Scrape Noon restaurant and menu data to help users gain invaluable insights into many dining options. Users can access comprehensive information such as restaurant names, cuisines, ratings, and menu items through web scraping techniques. This data empowers users to explore dining choices, compare menus, and make informed decisions. Additionally, businesses can utilize scraped data for market analysis, competitive intelligence, and menu optimization, enhancing their digital presence and offerings.
Steps to Create a Python Script for Scraping Noon Restaurant and Menu Data with Add-ons
Define Data Objectives: Clearly define the specific data you aim to scrape from Noon's website. It could include restaurant names, locations, cuisines, ratings, reviews, menu items, prices, and other relevant information.
Research Scraping Tools: Scraping Noon's restaurant and menu data with add-ons involves investigating Python libraries and frameworks, such as BeautifulSoup, Scrapy, or Selenium. Consider factors like ease of usage, compatibility with Noon's website structure, and the level of customization required.
Analyze Website Structure: Before writing any code, inspect the HTML structure of Noon's website using browser developer tools. Identify the necessary data elements, such as class names, IDs, or XPath expressions. Understanding the website's layout will help streamline the scraping process.
Script Development:
- Write Python scripts to automate the scraping process.
- Utilize the chosen scraping tool to send HTTP requests to Noon's server, retrieve HTML content, and parse it to extract relevant data.
- Implement logic to navigate different pages, such as pagination for restaurant listings.
Handle Dynamic Content: Noon's website may contain dynamic elements loaded via JavaScript. Ensure your scraping script can handle such content using a headless browser with Selenium or analyzing network requests to identify data sources.
Integration of Add-ons: Integrate additional functionalities or libraries to enhance the scraping process. For example, use Pandas for data manipulation or Scrapy middleware for custom request handling. Choose add-ons that align with your data objectives and technical requirements.
Error Handling and Logging: Use error handling mechanisms within your script to manage unexpected situations gracefully. Consider logging to record scraping activities, including successful data retrievals and any encountered errors, facilitating debugging and troubleshooting.
Testing and Refinement: Thoroughly test your scraping script on different scenarios and edge cases to ensure it retrieves accurate and complete data from Noon. Iterate on the script as needed, refining the code structure, improving error handling, and optimizing performance to achieve reliable and efficient data extraction.
Steps for Scraping
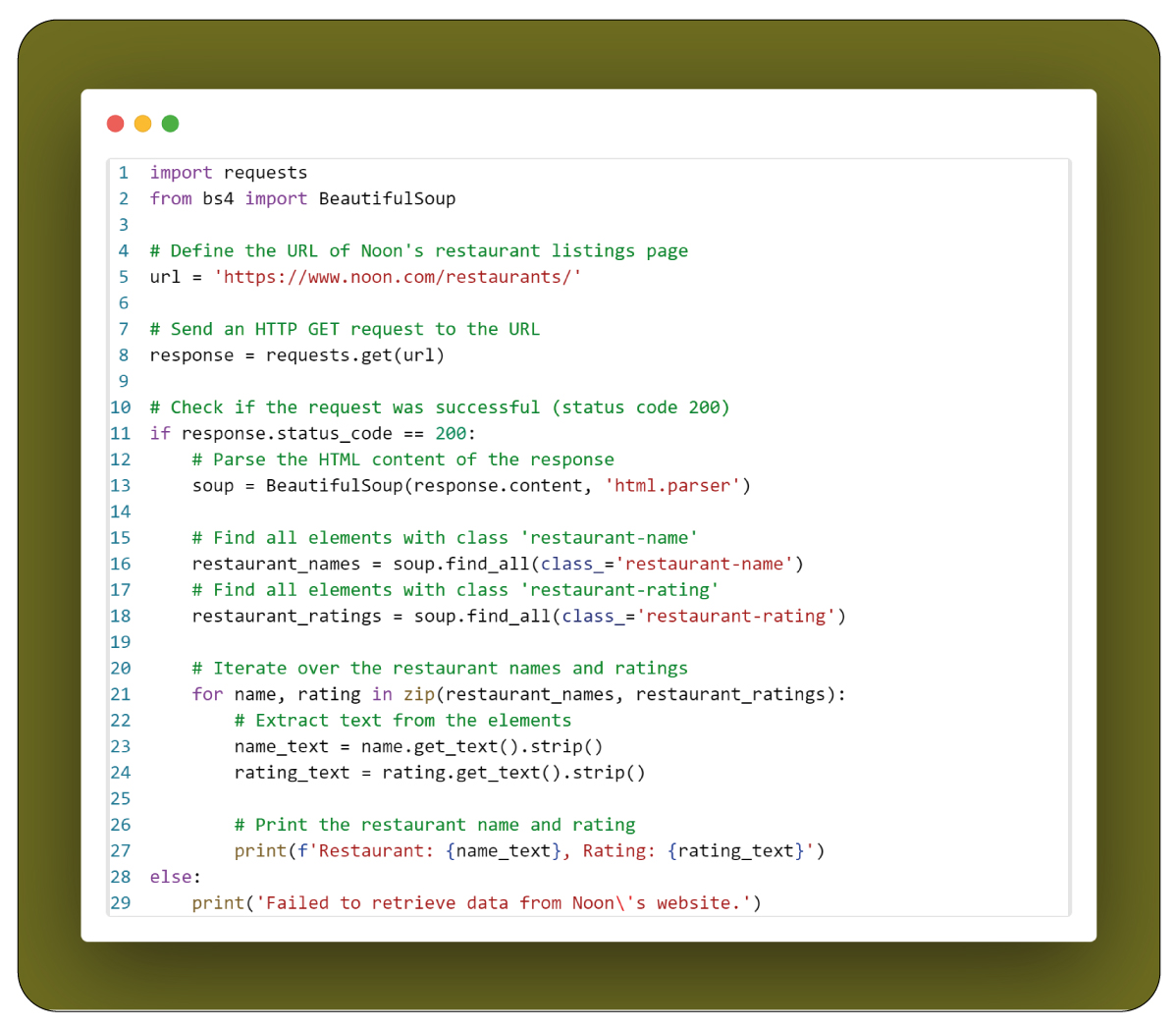
- We import the necessary libraries: requests for sending HTTP requests and BeautifulSoup for parsing HTML.
- We define the URL of Noon's restaurant listings page.
- We send an HTTP GET request to the URL using requests.get().
- We check if the request was successful (status code 200).
- If successful, we parse the HTML content using BeautifulSoup.
- We use find_all() to locate all elements with specific classes for restaurant names and ratings.
- We iterate over the found elements, extracting text content with get_text().
- Finally, we print the extracted restaurant names and ratings.
Conclusion: restaurant data scraper presents a powerful solution for consumers and businesses in the culinary landscape. By leveraging Python scripts enhanced with appropriate tools and techniques, users can extract comprehensive insights into dining options, including restaurant details, cuisines, ratings, and menu offerings. Our Pricing Intelligence solution empowers consumers to make informed dining decisions while enabling businesses to optimize their strategies, enhance their offerings, and stay competitive in digital dining. With the proper data extraction and analysis, scraping Noon's restaurant and menu data with add-ons opens up a world of culinary exploration and business opportunities.
At Product Data Scrape, our commitment to unwavering ethical standards permeates every aspect of our operations. Whether delivering Competitor Price Monitoring Services or engaging in Mobile App Data Scraping, our global presence across multiple offices ensures the steadfast delivery of exceptional, transparent services. We tailor our offerings to meet the diverse requirements of our esteemed clients, aiming for consistent excellence in every service provided.



































.webp)





